.svg)
Compute Engine for Iceberg, Delta Lake, Hudi: Query | ETL | Ingestion
Query, ETL, Real-time Ingest for Iceberg, Delta, Hudi, and Hive
The only engine built for the Agentic AI era
Cloud, On Premise, Hybrid. AI-native lakehouse compute engine.
60% Cost Savings. No migration from Databricks, Snowflake, Redshift, BigQuery. Runs Anywhere.
Save 60% without migrating from Databricks, Snowflake, Redshift, Fabric. 10x faster. Across Cloud, On-Prem, Hybrid.
Powered by the industry’s first Atomic Architecture, e6data defines a new frontier in processing efficiency, deployment flexibility and agent-native capabilities. See production results in weeks on your most expensive and challenging workloads.
.svg)
$1M
savings per quarter
Run anywhere
Public cloud, private cloud, hybrid
Agent-native
by design
DESIGN PRINCIPLES
Bringing proven software architecture principles into compute engine architecture
Existing engines trace their architectures to when they were first created (early 2010) when the cloud was in its infancy and VM-centric, monolithic architectures were the norm. e6data is built on powerful primitives and constructs that did not exist when the previous generation of engines were created.
.svg)
.svg)
e6data architecture
e6data has the industry’s only Atomic ArchitectureTM that delivers: unparalleled processing efficiency, deployment flexibility and interoperability
- Decentralized, decoupled services that make up the engine. Each granular communicates with others via defined contracts
- Each service can be controlled, sized, and scaled granularly and independently of the others
- Sizing and Scaling are both atomic (i.e. +/- 1 vCPU increments) compared to the large step jumps (e.g. L -> L x 2) that T-shirt sizing models involve
- No central coordinator / driver = No single processing bottleneck, No central point of failure.
w/o e6data
.png)
w/ e6data
.png)
w/o e6data
w/ e6data
.png)
w/o e6data
.png)
w/ e6data
.png)
Trusted by Data Teams at

“We achieved 1,000 QPS concurrencies with p95 SLAs of < 2s on near real-time data & complex queries. Other industry leaders couldn’t meet this even at a far higher TCO.”
Chief Operating Officer

“We’ve been impressed with e6data’s performance, concurrency, and granular scalability on our resource-intensive workloads.”
Head of Platform Engineering
Technology
How does e6data save you 50-60% on compute cost?
w/o e6data

w/ e6data

Comparison
Atomic vs Step-Jump Scaling: Cost & QPS Under Production Load
Line graph comparing legacy step-jump scaling with e6data’s atomic scaling across fluctuating query loads; cost labels show steep jumps for legacy ($25 → $100) versus granular increments for e6data ($15 → $74).

Benchmarks
Vs. legacy lakehouse engine
3.09x
Faster
TPC-DS
Delta
8 QPS
Vs. legacy QUERY engine
11.02x
Faster
TPC-DS
Fabric
30 cores
Query type: comparison
1.58x
Faster
TPC-DS
Delta
AWS
XS
Vs. legacy lakehouse engine
67.64%
Lower cost
TPC-DS
Delta
8QPS
Vs. legacy query engine
7.04x
Faster
TPC-DS
Iceberg
XS
Query type: logical
1.80x
Faster
TPC-DS
Delta
AWS
XS
Vs. legacy lakehouse engine
3.08x
Lower p99 latency
TPC-DS
Delta
8 QPS
e6data + Fabric
60.05%
Lower cost
TPC-DS
Fabric
30 cores
High Concurrency
1.20x
Faster
TPC-DS
Delta
AWS
XS
Vs. legacy lakehouse engine
3.09x
Faster
TPC-DS
Delta
8 QPS
Vs. legacy QUERY engine
11.02x
Faster
TPC-DS
Fabric
30 cores
Query type: comparison
1.58x
Faster
TPC-DS
Delta
AWS
XS
Vs. legacy lakehouse engine
67.64%
Lower cost
TPC-DS
Delta
8QPS
Vs. legacy query engine
7.04x
Faster
TPC-DS
Iceberg
XS
Query type: logical
1.80x
Faster
TPC-DS
Delta
AWS
XS
Vs. legacy lakehouse engine
3.08x
Lower p99 latency
TPC-DS
Delta
8 QPS
e6data + Fabric
60.05%
Lower cost
TPC-DS
Fabric
30 cores
High Concurrency
1.20x
Faster
TPC-DS
Delta
AWS
XS
.svg)
Use Cases
Run your most resource-intensive SQL and AI workloads
Get predictable SLAs, instant query responses, and radically lower compute costs—all with no query rewrites or app changes.
.svg)
.svg)
Developer Experience
Query everything, scale and secure fast on your own stack
Run SQL + AI workloads that auto scale, block bad jobs, run vector search, and stay secure with row/column masking—no tuning, no trust issues.
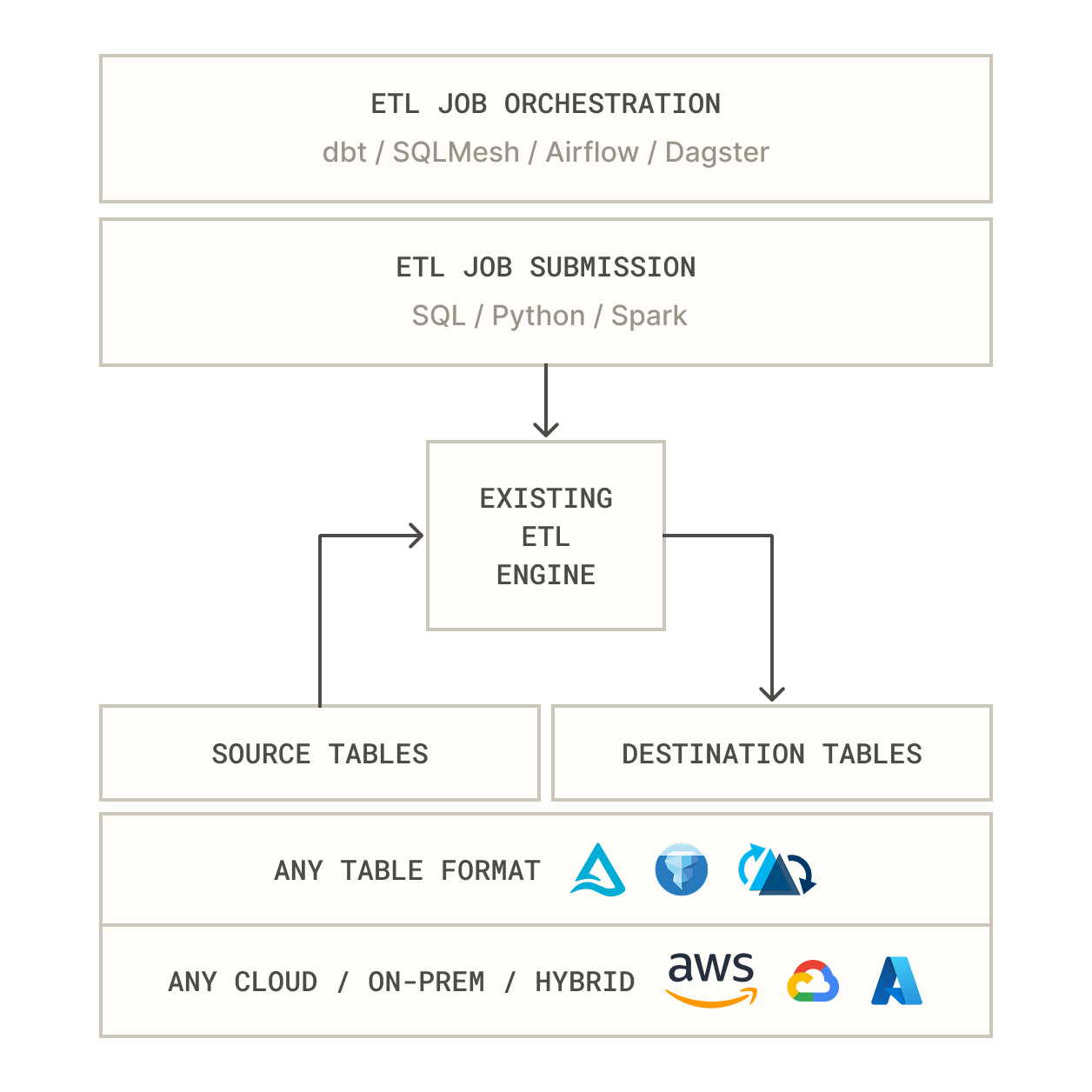
Runs with your data stack
Supports all lakehouses, table formats, catalogs, BI tools, and RAG apps—no custom code needed.

.svg)
.svg)
.svg)
.svg)
.svg)
.svg)
.svg)
.svg)













Lakehouse

Queries directly with zero data movement.
Table Format
.png)
Highly performant on all table formats.
Catalog
.png)
Plugs into any catalog; no rules rewrites.
Application
.png)
Connects to any BI, RAG app, chatbot tool
Governance
.png)
Governance ready: plug into your tools.
SQL meets AI, right in your lakehouse
Query structured and unstructured data with cosine similarity. No vector DBs. Just pure vector search.

Auto-scaling that adapts to query load
Set min and max, we handle the rest. Executors scale with load with no latency spikes, no job failures, no manual tuning.

Guardrails to stop “bad” queries early
Set thresholds per cluster. Log, alert, or cancel in real time before bad queries waste compute.

Sub-second streaming of data in your lake
Stream directly to your lakehouse, query with sub-second latency- query with SQL/Python. No Flink, no ETL, no learning curve.

Enterprise-grade security and governance
Row/column-level control, IAM integration, and audit-ready logs. SOC 2, ISO, HIPAA, and GDPR—secure by design, with no slowdown.

.svg)
.svg)
.svg)
Available at
.png)

.svg)