A Hands-On Guide to Snapshots and Time Travel in Apache Iceberg
By Karthic Rao and Fenil Jain on 15 Nov 2024

Snapshots and Time Travel in Apache Iceberg
Apache Iceberg is an open table format designed for managing petabyte-scale analytic datasets, providing a high-performance solution for modern data lakehouse architectures. By enabling object storage to serve as the backbone of the analytical stack, Iceberg allows organizations to leverage cost-effective and scalable storage solutions without compromising on performance. By addressing common challenges like data consistency, schema evolution, and performance, Iceberg has become a game-changer for handling large-scale data. This blog will explore how Iceberg's advanced snapshot creation and time travel features work, delving into the metadata file structure, snapshot log, and the atomic swap mechanism guaranteeing data consistency. Using hands-on examples, we’ll illustrate how Iceberg easily allows consistent data state retrieval and time travel queries. All the examples are built using dockers-compose so that it's easy to use without setting up any services on your machine.
Snapshot Creation
Snapshot forms one of Iceberg's fundamental abstractions, which unlocks a bunch of other features like time travel, re-constructing table state, and views. Every time an Iceberg table is updated—whether through insertions, deletions, or schema changes—Iceberg creates a new snapshot. Each snapshot writes these files:
- root metadata file
- manifest list file
- manifest file
- data files
File Hierarchy in Iceberg
Let's first understand how these files are laid out and what they contain at a higher level. Apache Iceberg organizes its data in a hierarchical file structure:
- Root Metadata File: It is the central metadata file containing the entire table state
- Manifest Lists: These are files referenced by the root metadata file that point to manifest files.
- Manifest Files: These files hold information about actual data files (such as Parquet, ORC, or Avro).
- Data Files: They contain the actual table data stored as Parquet files.
Diving in Detail
Setup
Now, to study these files in detail, let's try to localize them with the example provided here: https://iceberg.apache.org/spark-quickstart This is the docker-compose file:
version: "3"
services:
spark-iceberg:
image: tabulario/spark-iceberg
container_name: spark-iceberg
build: spark/
networks:
iceberg_net:
depends_on:
- rest
- minio
volumes:
- ./warehouse:/home/iceberg/warehouse
- ./notebooks:/home/iceberg/notebooks/notebooks
environment:
- AWS_ACCESS_KEY_ID=admin
- AWS_SECRET_ACCESS_KEY=password
- AWS_REGION=us-east-1
ports:
- 8888:8888
- 8080:8080
- 10000:10000
- 10001:10001
rest:
image: tabulario/iceberg-rest
container_name: iceberg-rest
networks:
iceberg_net:
ports:
- 8181:8181
environment:
- AWS_ACCESS_KEY_ID=admin
- AWS_SECRET_ACCESS_KEY=password
- AWS_REGION=us-east-1
- CATALOG_WAREHOUSE=s3://warehouse/
- CATALOG_IO__IMPL=org.apache.iceberg.aws.s3.S3FileIO
- CATALOG_S3_ENDPOINT=http://minio:9000
minio:
image: minio/minio
container_name: minio
environment:
- MINIO_ROOT_USER=admin
- MINIO_ROOT_PASSWORD=password
- MINIO_DOMAIN=minio
networks:
iceberg_net:
aliases:
- warehouse.minio
ports:
- 9001:9001
- 9000:9000
command: ["server", "/data", "--console-address", ":9001"]
mc:
depends_on:
- minio
image: minio/mc
container_name: mc
networks:
iceberg_net:
environment:
- AWS_ACCESS_KEY_ID=admin
- AWS_SECRET_ACCESS_KEY=password
- AWS_REGION=us-east-1
entrypoint: >
/bin/sh -c "
until (/usr/bin/mc config host add minio http://minio:9000 admin password) do echo '...waiting...' && sleep 1; done;
/usr/bin/mc rm -r --force minio/warehouse;
/usr/bin/mc mb minio/warehouse;
/usr/bin/mc policy set public minio/warehouse;
tail -f /dev/null
"
networks:
iceberg_net:docker-compose up. Once all the containers are up, we’ll enter a spark-sql prompt to create our table and write.
docker exec -it spark-iceberg spark-sqlCREATE TABLE demo.nyc.taxis
(
vendor_id bigint,
trip_id bigint,
trip_distance float,
fare_amount double,
store_and_fwd_flag string
PARTITIONED BY (vendor_id);
)
admin and password.
Now navigate to warehouse > nyc > taxis > metadata (note: we still need a data folder here). You will notice a file with format 00000-<uuid>.metadata.json. This is our table metadata file representing the newly created table.
At this point, without data and only containing the schema of the table, the directory tree looks like this:
.
└── nyc
└── taxis
└── metadata
└── 00000-b3b5b32f-77a0-4bd9-a642-89afcfd1db35.metadata.json
└── xl.metaRoot Table Metadata File
On downloading the file and viewing it, we get:
{
"format-version" : 2,
"table-uuid" : "64919af4-5340-4aba-aa5a-93002be409b0",
"location" : "s3://warehouse/nyc/taxis",
"last-sequence-number" : 0,
"last-updated-ms" : 1731430316331,
"last-column-id" : 5,
"current-schema-id" : 0,
"schemas" : [ {
"type" : "struct",
"schema-id" : 0,
"fields" : [ {
"id" : 1,
"name" : "vendor_id",
"required" : false,
"type" : "long"
}, {
"id" : 2,
"name" : "trip_id",
"required" : false,
"type" : "long"
}, {
"id" : 3,
"name" : "trip_distance",
"required" : false,
"type" : "float"
}, {
"id" : 4,
"name" : "fare_amount",
"required" : false,
"type" : "double"
}, {
"id" : 5,
"name" : "store_and_fwd_flag",
"required" : false,
"type" : "string"
} ]
} ],
"default-spec-id" : 0,
"partition-specs" : [ {
"spec-id" : 0,
"fields" : [ {
"name" : "vendor_id",
"transform" : "identity",
"source-id" : 1,
"field-id" : 1000
} ]
} ],
"last-partition-id" : 1000,
"default-sort-order-id" : 0,
"sort-orders" : [ {
"order-id" : 0,
"fields" : [ ]
} ],
"properties" : {
"owner" : "root",
"write.parquet.compression-codec" : "zstd"
},
"current-snapshot-id" : -1,
"refs" : { },
"snapshots" : [ ],
"statistics" : [ ],
"partition-statistics" : [ ],
"snapshot-log" : [ ],
"metadata-log" : [ ]
}
warehouse > nyc > taxis.
We will insert row entries into the empty table in this manner, this is the first time we’re writing the tabular data into the table:
INSERT INTO demo.nyc.taxis
VALUES (1, 1000371, 1.8, 15.32, 'N'), (2, 1000372, 2.5, 22.15, 'N'), (2, 1000373, 0.9, 9.01, 'N'), (1, 1000374, 8.4, 42.13, 'Y');| vendor_id | trip_id | trip_distance | fare_amount | store_and_fwd_flag |
|-----------|----------|---------------|-------------|---------------------|
| 1 | 1000371 | 1.8 | 15.32 | N |
| 1 | 1000374 | 8.4 | 42.13 | Y |
| 2 | 1000372 | 2.5 | 22.15 | N |
| 2 | 1000373 | 0.9 | 9.01 | N |
.
└── nyc
└── taxis
├── data
│ ├── vendor_id=1
│ │ └── 00000-4-72dc2f30-f9b8-4e7f-af24-384ea79952ea-0-00001.parquet
│ │ └── xl.meta
│ └── vendor_id=2
│ └── 00000-4-72dc2f30-f9b8-4e7f-af24-384ea79952ea-0-00002.parquet
│ └── xl.meta
└── metadata
├── 00000-b3b5b32f-77a0-4bd9-a642-89afcfd1db35.metadata.json
│ └── xl.meta
├── 00001-ca824b7e-7e46-4c0c-b58f-2b6a55b87eac.metadata.json
│ └── xl.meta
├── 07b8f402-ec35-4eaf-87f2-a351d9f2b13d-m0.avro
│ └── xl.meta
└── snap-326927364746531255-1-07b8f402-ec35-4eaf-87f2-a351d9f2b13d.avro
└── xl.meta
Snapshot File
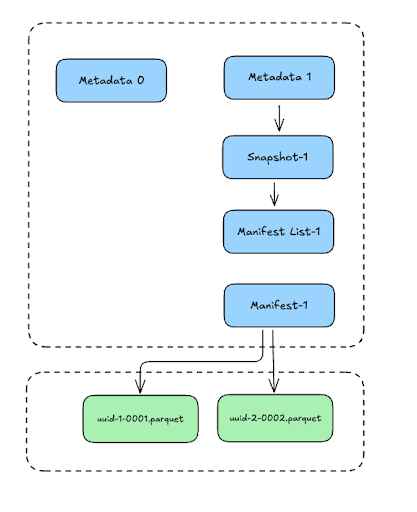 Let's download our new JSON file from the browser and explore it:
Let's download our new JSON file from the browser and explore it:
{
"format-version" : 2,
"table-uuid" : "64919af4-5340-4aba-aa5a-93002be409b0",
"location" : "s3://warehouse/nyc/taxis",
"last-sequence-number" : 1,
"last-updated-ms" : 1731430821537,
"last-column-id" : 5,
"current-schema-id" : 0,
"schemas" : [ {
"type" : "struct",
"schema-id" : 0,
"fields" : [ {
"id" : 1,
"name" : "vendor_id",
"required" : false,
"type" : "long"
}, {
"id" : 2,
"name" : "trip_id",
"required" : false,
"type" : "long"
}, {
"id" : 3,
"name" : "trip_distance",
"required" : false,
"type" : "float"
}, {
"id" : 4,
"name" : "fare_amount",
"required" : false,
"type" : "double"
}, {
"id" : 5,
"name" : "store_and_fwd_flag",
"required" : false,
"type" : "string"
} ]
} ],
"default-spec-id" : 0,
"partition-specs" : [ {
"spec-id" : 0,
"fields" : [ {
"name" : "vendor_id",
"transform" : "identity",
"source-id" : 1,
"field-id" : 1000
} ]
} ],
"last-partition-id" : 1000,
"default-sort-order-id" : 0,
"sort-orders" : [ {
"order-id" : 0,
"fields" : [ ]
} ],
"properties" : {
"owner" : "root",
"write.parquet.compression-codec" : "zstd"
},
"current-snapshot-id" : 5288760946744945553,
"refs" : {
"main" : {
"snapshot-id" : 5288760946744945553,
"type" : "branch"
}
},
"snapshots" : [ {
"sequence-number" : 1,
"snapshot-id" : 5288760946744945553,
"timestamp-ms" : 1731430821537,
"summary" : {
"operation" : "append",
"spark.app.id" : "local-1731429992596",
"added-data-files" : "2",
"added-records" : "4",
"added-files-size" : "3074",
"changed-partition-count" : "2",
"total-records" : "4",
"total-files-size" : "3074",
"total-data-files" : "2",
"total-delete-files" : "0",
"total-position-deletes" : "0",
"total-equality-deletes" : "0"
},
"manifest-list" : "s3://warehouse/nyc/taxis/metadata/snap-5288760946744945553-1-34ebd771-5245-4ca7-8cab-d80b094bbcd0.avro",
"schema-id" : 0
} ],
"statistics" : [ ],
"partition-statistics" : [ ],
"snapshot-log" : [ {
"timestamp-ms" : 1731430821537,
"snapshot-id" : 5288760946744945553
} ],
"metadata-log" : [ {
"timestamp-ms" : 1731430316331,
"metadata-file" : "s3://warehouse/nyc/taxis/metadata/00000-0fbb5ecb-6357-4571-bd80-97ba28994012.metadata.json"
} ]
}
snapshot-idparent-snapshot-idsequence-numbertimestamp-msmanifest-listmanifestssummaryschema-idfirst-row-id
insert operation, which has an append type. We added four records, reflected by the added-records. The number of data files added is mentioned by added-data-files. We can verify this by visiting warehouse > nyc > taxis > data. You will observe two folders, each containing a single file placed according to the partition key.Manifest List File
As the name suggests, a manifest list file lists the manifest file(s) associated with a particular snapshot. These manifest files point to data files containing rows of data in the table.
Let’s say a row is inserted at snapshot S1(=M1 -- corresponding manifest file) and updated later on snapshot S2(=M2 -- corresponding manifest file). The manifest list of S2 will contain M1 and M2.
Since this is an avro file, we can't inspect its text directly. However, we can leverage spark-sql to query these files. Firstly, let's try to see the snapshot by running:
select snapshot_id, manifest_list from demo.nyc.taxis.snapshots;8253356480484172902 s3://warehouse/nyc/taxis/metadata/snap-8253356480484172902-1-b8ea2e6e-979f-4511-a3dd-9d155ced2da1.avros3://warehouse/nyc/taxis/metadata/snap-8253356480484172902-1-b8ea2e6e-979f-4511-a3dd-9d155ced2da1.avro.
Next, let's check the contents of this manifest list by running:
select * from demo.nyc.taxis.manifests;0 s3://warehouse/nyc/taxis/metadata/b8ea2e6e-979f-4511-a3dd-9d155ced2da1-m0.avro 7211 0 8253356480484172902 2 0 0 0 0 0 [{"contains_null":false,"contains_nan":false,"lower_bound":"1","upper_bound":"2"}]s3://warehouse/nyc/taxis/metadata/b8ea2e6e-979f-4511-a3dd-9d155ced2da1-m0.avro, and some metadata:[{"contains_null":false,"contains_nan":false,"lower_bound":"1","upper_bound":"2"}]
The manifest files contain not only the path to the data files but also metadata with useful statistics about them.
Here are some quick statistics the metadata inside the manifest files provide:
- does contain
nullvalues - does not contain
nanvalues vendor_idhas lower bound as 1vendor_idhas lower bound as 2
Manifest File
Let's check the contents of the manifest file by running:
select * from demo.nyc.taxis.files;;0 s3://warehouse/nyc/taxis/data/vendor_id=1/00000-4-49cbfb21-063f-41d3-b9bf-04a6a991739a-0-00001.parquet PARQUET 0 {"vendor_id":1} 2 1516 {1:70,2:48,3:40,4:48,5:42} {1:2,2:2,3:2,4:2,5:2} {1:0,2:0,3:0,4:0,5:0} {3:0,4:0} {1:,2:�C,3:ff�?,4:�p=
ף.@,5:N} {1:,2:�C,3:ffA,4:q=
ףE@,5:Y} NULL [4] NULL 0
{
"fare_amount": {
"column_size": 48,
"value_count": 2,
"null_value_count": 0,
"nan_value_count": 0,
"lower_bound": 15.32,
"upper_bound": 42.13
},
"store_and_fwd_flag": {
"column_size": 42,
"value_count": 2,
"null_value_count": 0,
"nan_value_count": null,
"lower_bound": "N",
"upper_bound": "Y"
},
"trip_distance": {
"column_size": 40,
"value_count": 2,
"null_value_count": 0,
"nan_value_count": 0,
"lower_bound": 1.8,
"upper_bound": 8.4
},
"trip_id": {
"column_size": 48,
"value_count": 2,
"null_value_count": 0,
"nan_value_count": null,
"lower_bound": 1000371,
"upper_bound": 1000374
},
"vendor_id": {
"column_size": 70,
"value_count": 2,
"null_value_count": 0,
"nan_value_count": null,
"lower_bound": 1,
"upper_bound": 1
}
}
---------
0 s3://warehouse/nyc/taxis/data/vendor_id=2/00000-4-49cbfb21-063f-41d3-b9bf-04a6a991739a-0-00002.parquet PARQUET 0 {"vendor_id":2} 2 1558 {1:70,2:48,3:40,4:48,5:67} {1:2,2:2,3:2,4:2,5:2} {1:0,2:0,3:0,4:0,5:0} {3:0,4:0} {1:,2:�C,3:fff?,4:��Q�"@,5:N} {1:,2:�C,3: @,4:fffff&6@,5:N} NULL [4] NULL 0
{
"fare_amount": {
"column_size": 48,
"value_count": 2,
"null_value_count": 0,
"nan_value_count": 0,
"lower_bound": 9.01,
"upper_bound": 22.15
},
"store_and_fwd_flag": {
"column_size": 67,
"value_count": 2,
"null_value_count": 0,
"nan_value_count": null,
"lower_bound": "N",
"upper_bound": "N"
},
"trip_distance": {
"column_size": 40,
"value_count": 2,
"null_value_count": 0,
"nan_value_count": 0,
"lower_bound": 0.9,
"upper_bound": 2.5
},
"trip_id": {
"column_size": 48,
"value_count": 2,
"null_value_count": 0,
"nan_value_count": null,
"lower_bound": 1000372,
"upper_bound": 1000373
},
"vendor_id": {
"column_size": 70,
"value_count": 2,
"null_value_count": 0,
"nan_value_count": null,
"lower_bound": 2,
"upper_bound": 2
}
}
s3://warehouse/nyc/taxis/data/vendor_id=1/00000-4-49cbfb21-063f-41d3-b9bf-04a6a991739a-0-00001.parquets3://warehouse/nyc/taxis/data/vendor_id=2/00000-4-49cbfb21-063f-41d3-b9bf-04a6a991739a-0-00002.parquet
PARQUET format to store data, and the metadata with statistics are stored inside the manifest files. These statistics help trim data before reading all data files in detail. For instance, In the last column of the manifest file, we have specific stats for each of the columns for fare_amount:- fare_item
- column's size is 48
- value's count is 2
- there are no null values
- there are no nan values
- lower bound is 9.02
- upper bound is 22.15
Parquet Data File
We can query back our data using:
select * from demo.nyc.taxis.files;pqrs cat 00000-4-49cbfb21-063f-41d3-b9bf-04a6a991739a-0-00001.parquet
pqrs cat 00000-4-49cbfb21-063f-41d3-b9bf-04a6a991739a-0-00002.parquet##################################################################
File: 00000-4-49cbfb21-063f-41d3-b9bf-04a6a991739a-0-00001.parquet
##################################################################
{vendor_id: 1, trip_id: 1000371, trip_distance: 1.8, fare_amount: 15.32, store_and_fwd_flag: "N"}
{vendor_id: 1, trip_id: 1000374, trip_distance: 8.4, fare_amount: 42.13, store_and_fwd_flag: "Y"}##################################################################
File: 00000-4-49cbfb21-063f-41d3-b9bf-04a6a991739a-0-00002.parquet
##################################################################
{vendor_id: 2, trip_id: 1000372, trip_distance: 2.5, fare_amount: 22.15, store_and_fwd_flag: "N"}
{vendor_id: 2, trip_id: 1000373, trip_distance: 0.9, fare_amount: 9.01, store_and_fwd_flag: "N"}Leveraging Snapshots for Time Travel Queries
With Iceberg, we can query historical data states as they existed in any past snapshot. Using the snapshot log, we can retrieve and use any previous snapshot ID to access the table’s state at that specific time. Let's see this in action: We only have one snapshot representing one batch of data we wrote into the table. Let’s write another row of data into the table, thus altering the state of the table and leading to the creation of the new snapshot. (Note: In ideal production environments, you never write one entry at a time into Iceberg tables; you need thousands of records/rows and write at once. We’ll learn more about this in future blogs).
INSERT INTO demo.nyc.taxis VALUES (3, 1000671, 2.1, 11.67, 'W');| vendor_id | trip_id | trip_distance | fare_amount | store_and_fwd_flag |
|-----------|----------|---------------|-------------|---------------------|
| 3 | 1000671 | 2.1 | 11.67 | W |
| 1 | 1000371 | 1.8 | 15.32 | N |
| 1 | 1000374 | 8.4 | 42.13 | Y |
| 2 | 1000372 | 2.5 | 22.15 | N |
| 2 | 1000373 | 0.9 | 9.01 | N |
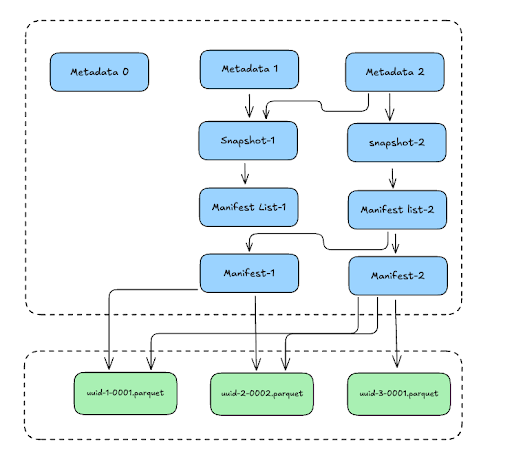 As you can see, the new snapshot creates a new tree of files to represent the latest state of the table. But, notice that the new manifest list (Manifest list-2) also points to the Manifest file (Manifest-1) from the first snapshot to represent the data from the first write/snapshot. The new state of the table now includes the data from the first snapshot + the data from the second snapshot.
This tree structure underneath, allows us to retrieve the state of the table at any given version of the snapshot, which we can use as the time travel feature. This is how, we can load our first snapshot by specifying the snapshot ID:
As you can see, the new snapshot creates a new tree of files to represent the latest state of the table. But, notice that the new manifest list (Manifest list-2) also points to the Manifest file (Manifest-1) from the first snapshot to represent the data from the first write/snapshot. The new state of the table now includes the data from the first snapshot + the data from the second snapshot.
This tree structure underneath, allows us to retrieve the state of the table at any given version of the snapshot, which we can use as the time travel feature. This is how, we can load our first snapshot by specifying the snapshot ID:
select * from demo.nyc.taxis version as of 8253356480484172902;1 1000371 1.8 15.32 N
1 1000374 8.4 42.13 Y
2 1000372 2.5 22.15 N
2 1000373 0.9 9.01 N
.
└── nyc
└── taxis
├── data
│ ├── vendor_id=1
│ │ └── 00000-4-72dc2f30-f9b8-4e7f-af24-384ea79952ea-0-00001.parquet
│ │ └── xl.meta
│ ├── vendor_id=2
│ │ └── 00000-4-72dc2f30-f9b8-4e7f-af24-384ea79952ea-0-00002.parquet
│ │ └── xl.meta
│ └── vendor_id=3
│ └── 00000-6-dd109de5-b321-4a30-8a75-6d75c3cc2816-0-00001.parquet
│ └── xl.meta
└── metadata
├── 00000-b3b5b32f-77a0-4bd9-a642-89afcfd1db35.metadata.json
│ └── xl.meta
├── 00001-ca824b7e-7e46-4c0c-b58f-2b6a55b87eac.metadata.json
│ └── xl.meta
├── 00002-b17fc0f7-28d5-4ea9-9ff3-f4cfb34d5887.metadata.json
│ └── xl.meta
├── 07b8f402-ec35-4eaf-87f2-a351d9f2b13d-m0.avro
│ └── xl.meta
├── 4f8b88b1-1de9-46ba-a4b7-0ecd078e3bce-m0.avro
│ └── xl.meta
├── snap-326927364746531255-1-07b8f402-ec35-4eaf-87f2-a351d9f2b13d.avro
│ └── xl.meta
└── snap-604029234644286416-1-4f8b88b1-1de9-46ba-a4b7-0ecd078e3bce.avro
└── xl.meta
Conclusion
Iceberg’s snapshot creation and time travel features are built on a robust hierarchical metadata structure. The root metadata file acts as the primary point of reference for the table’s state, and the manifest list acts as a pointer to the manifest files, which in turn contain the path and statistics about the actual data files containing the table data. Thank you for your time reading this blog; stay tuned to more episodes around the Apache Iceberg open-table format internals!