Deep dive behind e6data’s Gen3 Lakehouse compute engine’s architecture and design principles.
Today, enterprises are grappling with an unprecedented surge in compute demand - primarily driven by the exponential adoption of mission-critical analytics and GenAI workloads. Despite comprising just 10% of the overall mix, such heavy workloads consume 80% of data engineering resources and attention. Examples include Customer-facing data products, Large-scale scheduled exports and Data sharing, Near Real Time (NRT) Analytics, and Production-ready GenAI applications.
They are intrinsically compute-intensive or “heavy” because of factors like high query volumes, large-scale data processing, queries on near real-time (NRT) data, and the need for strict p50/p95 latency expectations from end-users. Open table formats like Iceberg, Delta and Hudi are an important part of the solution because they help enterprises take ownership and control over their data. However, compute lock-in remains a major issue, especially with GenAI on the horizon.
Let’s take a deep dive on how we solved these challenges!
Examining the status quo
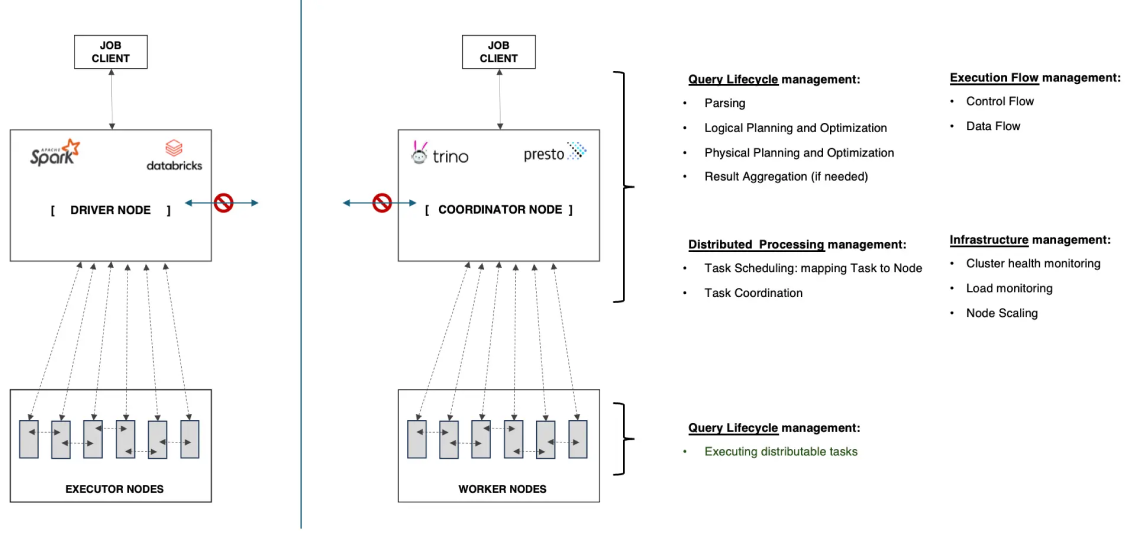
Problem with the status quo: Under high concurrency or complex query load, the central driver/coordinator node becomes the bottleneck and the single point of failure.
A deeper look at Spark and Presto / Trino
Data platform and data engineering teams operating at scale have found that such an approach has key challenges:
The Coordinator / Driver becomes a Single point of Failure (SPOF)
This central component holds the state of all queries. Therefore, anytime the coordinator suffers a crash, this impacts all queries in the system (both in-progress, as well as queued).
The various activities that are performed in this non-scalable central component compete for scarce resources. This is particularly pronounced under various forms of system load (such as concurrency, complex queries) and scale (large number of executors). This results in degraded performance for all queries in the system - which in turn may leads to failures in the central coordinator.
Inefficient Resource Utilisation (especially in executors) leading to Poor Performance
The approach to distributed processing is static and centrally controlled, where the coordinator allocates distributable tasks to individual executor nodes and coordinates the dependencies between such tasks. Such decisions are made in a static manner prior to execution (i.e. based on an up-front view of cluster load). Such decisions are impossible to get right in a complex distributed system since they cannot account for incorrect estimates due to changes in load due to concurrency and/or query complexity, unequal load distribution load due to data skew, etc.
Another challenge arises from the centrally managed execution flow which follows a pull-based implementation. Signalling for both the control flow as well as data flow originates from the central component – i.e. Coordinator / Driver. As outlined earlier, this central component is often overwhelmed under load, concurrency, and cluster scale. Under such conditions, we commonly find executors at low utilisation levels despite seeing degradation in query latencies and throughput.
Inability to guarantee latency and throughput SLAs despite executors being able to scale out
Several applications today require deterministic p90 / 95 / 99 latencies to be guaranteed. Under a static approach to distributed processing, newly added executors (as a result of executor scale out) do not benefit in-progress queries since the mapping of distributable tasks to nodes is decided prior to start of execution. Thus, such an approach makes it impossible to offer guarantees around latency and throughput – despite having the ability to scale out.
How can we improve on existing engines?
Disaggregated, Stateless, Architecture with (near) single purpose services
Recognising the challenges of a central, stateful component like the Coordinator / Driver in Presto / Spark, we opted for an architecture that was Disaggregated, Stateless, and Kubernetes-native. This enables us to make each component:
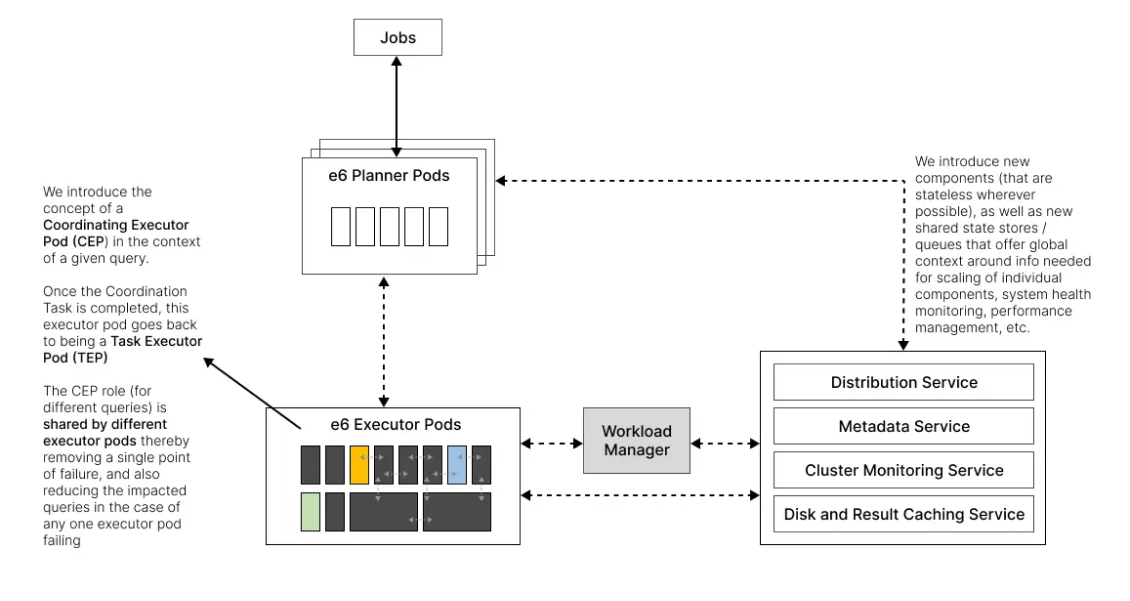
e6data Architecture: Disaggregated, Stateless with no Single Point of Failure
Decentralised, Dynamic approach to distributed processing and execution
Decisions of which task runs on which executor resource (an executor pod in our case), are made in a decentralised manner. As an executor pod has available resources, it picks up tasks from a global queue and commences execution. This method also removes the need for centralised coordination between tasks. An added benefit of such approach is that it is far less susceptible to data skew leading to uniform utilisation across executor resources. This in-turn avoids idle time and under—utilisation of executors.
In contrast to the static (i.e. prior to execution) approach to allocating tasks to executor resources, our dynamic approach makes these decisions in a dynamic or on-the-fly basis. Our approach benefits from a far more reliable view of the live state of executor load – and therefore removes the possibility of incorrect resource allocations leading to poor cluster utilisation.
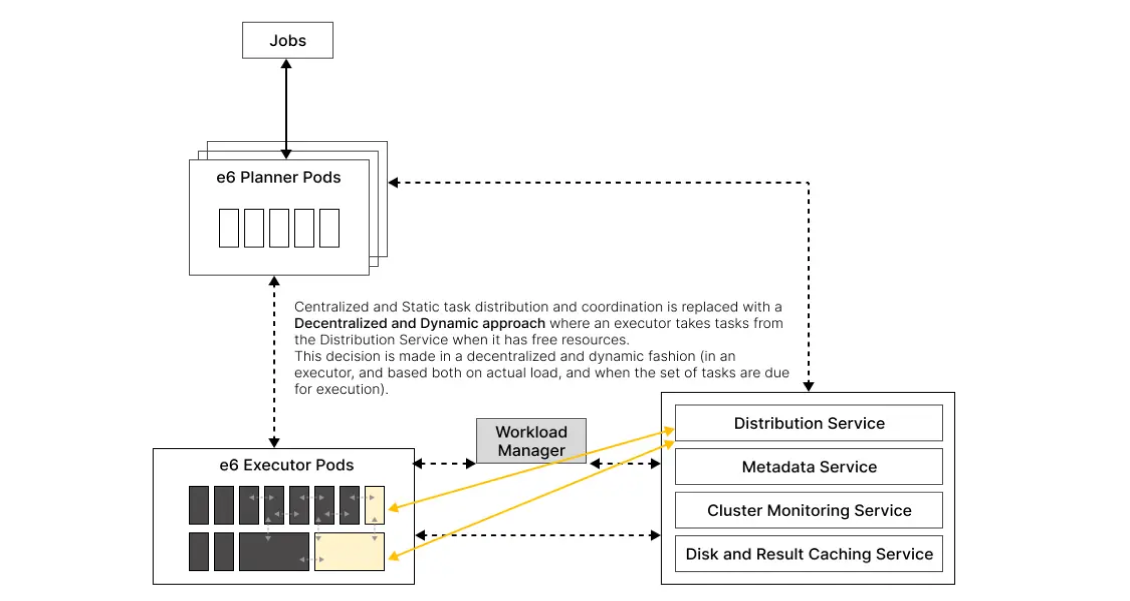
e6data Distributed Processing: Decentralized + Dynamic approach to Task Scheduling & Coordination
As a result of these design choices, e6data can address the compute needs of enterprises on heavy workloads, while delivering: 5x+ higher performance, 50%+ lower costs, and escape from ecosystem lock-in on compute. We are the only truly format-neutral SQL compute engine that delivers the same price-performance regardless of the choice of open table format, catalog, cloud platform, etc. To know more, feel free to reach out to us at hello@e6x.io and we will get in touch with you shortly.