Under the Hood of Apache Iceberg: An Inside Look at the Metadata Evolution After Compaction
By Karthic Rao and Shreyas Mishra on 03 Jan 2025

Apache Iceberg Metadata Evolution After Compaction
In traditional data warehouses, storage and computing are tightly integrated.
By contrast, lakehouses–built with the Apache Iceberg format and Delta Lake–embrace a separation of storage and compute, leveraging scalable cloud object storage systems like S3 or high-performance object storage solutions like MinIO for data storage while enabling independent compute engines for querying and processing.
This approach provides flexibility and scalability but introduces new challenges for ingesting streaming data into the object storage, including the “Small file problem.”
This blog guides you in tackling the “small file problem” challenge through compaction using Apache Spark and Apache Amoro. It provides an in-depth look at the evolution of metadata before and after compaction and how it optimizes data for efficient querying. But before that, let’s step back and understand a little about the Apache Iceberg.
Emergence of Apache Iceberg as the Popular Choice
The rise of the data lakehouse architecture (also called the open-table format), separated the storage and compute layers for the analytical processing of structured data, marking a pivotal shift in data storage and processing. The lakehouse architecture has various implementations or specifications, among which Delta, Hudi, Iceberg, and Paimon are the top contenders.
At this point, Apache Iceberg is the clear winner. Apache Iceberg, like other lakehouse architectures, is a set of rules or specifications for storing structured data inside object storages to enable efficient analytics at scale.
This blog assumes that you are familiar with the basic concepts of the Iceberg, like Manifest Files, Manifest Lists, Partitions, Data Files, Snapshots, and so on. If you’re new to Iceberg, a quick read of our blog on Iceberg basics helps you follow along easily.
While Iceberg tables are great, what’s the point of an Iceberg table without data? Ingesting data into Iceberg tables comes with its own set of challenges. Let’s delve into one of them in the next section.
The Small File Problem
Object storage systems like S3 or MinIO are designed to store bulk data files, not thousands or millions of tiny ones. Each time a file is created, there is overhead—metadata gets written, connections are established, and the file system or object store must track that file. The constant overhead would skyrocket if every incoming JSON data entry were written as an individual file (imagine every row from a stream creating its .json file). Querying engines would then be forced to scan many tiny files, dramatically slowing down reads because each open and read operation adds latency.
Batching is the natural solution: accumulating a group of rows (e.g., a few thousand or even millions of records) and compressing them into a single parquet file. This reduces the total file count and minimizes the overhead of handling file operations. Over time, however, if your ingestion is near real-time or micro-batched, you may still generate many small-sized parquet files—especially under high data ingestion rates. This accumulation of small files is what we refer to as the small file problem.
When files are too small and too numerous:
- Query engines must open and read every file, creating substantial performance penalties.
- Metadata operations (e.g., listing all files and retrieving file sizes) become bottlenecks.
- Storage systems can become overwhelmed, tracking so many tiny objects.
Hence, we typically aim for larger files to strike a balance between real-time ingestion and performant queries. Yet, inevitably, when you ingest data very frequently in small batches, you end up with many small files—and at that point, a compaction process becomes essential to consolidate these small files into fewer, larger files, improving both query performance and overall system efficiency.
In our next section, we will explore how to perform the compaction process using Apache Amoro and examine the evolution of Iceberg table metadata.
Apache Amoro Before we get deeper into the rabbit hole, let’s get a brief understanding of Apache Amoro. We will need this because we will run the compaction on Apache Iceberg tables using Spark and Apache Amoro to address the small file problem.
Apache Amoro is an upcoming open-source Lakehouse management system designed to optimize and manage data lakes that use open table formats such as Apache Iceberg, Delta Lake, Apache Hudi, and Paimon.
The Setup
Docker Compose Configuration
Let’s start this hands-on guide setting up the dependencies, including running Spark for compaction. To make things easy for you, all the dependencies for this blog will be set up using docker-compose. So, save the following configuration as docker-compose.yml
version: "3"
services:
spark-iceberg:
image: tabulario/spark-iceberg:3.5.1_1.5.0
container_name: spark-iceberg
build: spark/
networks:
- iceberg_net
depends_on:
- rest
- minio
volumes:
- ./lakehouse/:/home/iceberg/lakehouse
- ./notebooks:/home/iceberg/notebooks/notebooks
environment:
- AWS_ACCESS_KEY_ID=admin
- AWS_SECRET_ACCESS_KEY=password
- AWS_REGION=us-east-1
- SPARK_SQL_EXECUTION_ARROW_PYSPARK_ENABLED=true
ports:
- "8888:8888"
- "8080:8080"
- "10000:10000"
- "10001:10001"
- "4041:4041"
rest:
image: tabulario/iceberg-rest
container_name: iceberg-rest
networks:
- iceberg_net
ports:
- "8181:8181"
environment:
- AWS_ACCESS_KEY_ID=admin
- AWS_SECRET_ACCESS_KEY=password
- AWS_REGION=us-east-1
- CATALOG_WAREHOUSE=s3://lakehouse/
- CATALOG_IO__IMPL=org.apache.iceberg.aws.s3.S3FileIO
- CATALOG_S3_ENDPOINT=http://minio:9000
minio:
image: minio/minio
container_name: minio
volumes:
- ./minio/data:/data
environment:
- MINIO_ROOT_USER=admin
- MINIO_ROOT_PASSWORD=password
- MINIO_DOMAIN=minio
networks:
iceberg_net:
aliases:
- lakehouse.minio
ports:
- "9001:9001"
- "9000:9000"
command: ["server", "/data", "--console-address", ":9001"]
mc:
depends_on:
- minio
image: minio/mc
container_name: mc
networks:
- iceberg_net
environment:
- AWS_ACCESS_KEY_ID=admin
- AWS_SECRET_ACCESS_KEY=password
- AWS_REGION=us-east-1
entrypoint: >
/bin/sh -c "
until (/usr/bin/mc config host add minio http://minio:9000 admin password) do echo '...waiting...' && sleep 1; done;
/usr/bin/mc rm -r --force minio/lakehouse/;
/usr/bin/mc mb minio/lakehouse/;
/usr/bin/mc policy set public minio/lakehouse/;
tail -f /dev/null
"
amoro:
image: apache/amoro
container_name: amoro
ports:
- "8081:8081"
- "1630:1630"
- "1260:1260"
environment:
- JVM_XMS=1024
networks:
- iceberg_net
volumes:
- ./amoro:/tmp/lakehouse/
command: ["/entrypoint.sh", "ams"]
tty: true
stdin_open: true
networks:
iceberg_net:
driver: bridge
Starting the Environment
Let’s start the dependency container services utilizing the docker-compose config file above.
Run the following command to commence the Docker services:
$ docker-compose up -d
.png)
We have five containers running. Here’s what they do.
Iceberg-rest: REST Apache Iceberg catalog API service for central metadata management.
Spark-iceberg: Pre-built environment with Spark and Iceberg configured to run SQL queries on iceberg tables.
MinIO: Open-source S3-compatible Object storage service to store our data as the iceberg table inside the object storage bucket.
MinIO/MC: CLI tool to manage and configure Minio object storage, including creating buckets and settings permissions.
Apache Amoro: Amoro is an open-source Lakehouse management system for managing Iceberg tables. We’ll be using it to perform compaction.
The Dataset
Now that all the dependency services are running, let’s get into the container and access the dataset used for the rest of the tutorial. We’ll use the NYC Yellow Taxi trip data for January and February 2022. You do not need to download the dataset, as it has already been baked into the container stored as parquet files.
In most real-world scenarios, we’ll ingest data into Iceberg from streaming sources like Kafka, Redpanda, Kinesis, Apache Pulsar, RabbitMQ, etc. But here, we are using the existing parquet data files to load an Iceberg table with data for demonstration purposes. The data is still stored as parquet files inside Iceberg tables. But, unlike these plain parquet data files (also referred to as data lake architecture), data lakehouses like Iceberg create a bunch of hierarchical metadata files alongside the parquet files, which enables table abstraction and ACID transaction capabilities on the data.
If you’re curious about the difference between storing data as plain parquet files and a lakehouse open-table format like Delta or Iceberg, read this interesting article.
The plain parquet dataset is in the container’s /home/iceberg/data/ directory. Let’s verify the data’s existence in the parquet file format before we create a new Iceberg table and load this dataset into the table.
We’ll exec into the container to see the plain parquet data files:
$ docker exec -it spark-iceberg bash
root@31d643fb14db:/opt/spark# ls /home/iceberg/data/
nyc_film_permits.json yellow_tripdata_2021-05.parquet yellow_tripdata_2021-07.parquet yellow_tripdata_2021-09.parquet yellow_tripdata_2021-11.parquet yellow_tripdata_2022-01.parquet yellow_tripdata_2022-03.parquet
yellow_tripdata_2021-04.parquet yellow_tripdata_2021-06.parquet yellow_tripdata_2021-08.parquet yellow_tripdata_2021-10.parquet yellow_tripdata_2021-12.parquet yellow_tripdata_2022-02.parquet yellow_tripdata_2022-04.parquet
Loading Data into Iceberg Tables
Creating Temporary Views
Let’s create temporary views in Spark SQL to load data from the Parquet files into an Iceberg table. Temporary views are necessary for loading the parquet and setting it up to create an iceberg table later using the same data inside S3-compatible Minio Object storage. Next, connect to the Spark shell inside the Docker container:
docker exec -it spark-iceberg spark-sql
Create temporary views for the Parquet files so that we can use them later to insert the iceberg table:
-- For January data
CREATE OR REPLACE TEMPORARY VIEW parquet_temp_view
USING parquet
OPTIONS (
path '/home/iceberg/data/yellow_tripdata_2022-01.parquet'
);
-- For February data
CREATE OR REPLACE TEMPORARY VIEW parquet_temp_view2
USING parquet
OPTIONS (
path '/home/iceberg/data/yellow_tripdata_2022-02.parquet'
);
Creating the Partitioned Table
Now that we have created temporary views with data from local parquet files, let’s create an Iceberg table to load temporary view data into it. This table schema represents the NYC Taxi trip records, partitioned by payment_type.
CREATE TABLE demo.nyc.taxis_partitioned (
VendorID BIGINT,
tpep_pickup_datetime TIMESTAMP,
tpep_dropoff_datetime TIMESTAMP,
passenger_count DOUBLE,
trip_distance DOUBLE,
RatecodeID DOUBLE,
store_and_fwd_flag STRING,
PULocationID BIGINT,
DOLocationID BIGINT,
payment_type BIGINT,
fare_amount DOUBLE,
extra DOUBLE,
mta_tax DOUBLE,
tip_amount DOUBLE,
tolls_amount DOUBLE,
improvement_surcharge DOUBLE,
total_amount DOUBLE,
congestion_surcharge DOUBLE,
airport_fee DOUBLE
)
USING ICEBERG
PARTITIONED BY (
payment_type
);
Adding Data to the Partitioned Table
Now that we have our temporary view and partitioned table ready, let’s Insert data into it from the temporary views:
First INSERT operation: Creating an initial snapshot
INSERT INTO demo.nyc.taxis_partitioned SELECT * FROM parquet_temp_view;
Second INSERT operation:
INSERT INTO demo.nyc.taxis_partitioned SELECT * FROM parquet_temp_view2;
Now we have an Iceberg table partitioned by payment_type with data.
To summarise: We have performed two insert operations, each adding six new files. After these two appends, the table has 12 data files, many of which could be considered small. The Iceberg metadata at this stage includes:
- Metadata JSON – It is the main JSON file (like
00002-...metadata.json) pointing to the current snapshot of the table. - Manifest List Files – These are the Avro files that maintain a list of manifest files that belong to the given snapshot.
- Manifest Files – These are the Avro files detailing individual data files added or deleted within that snapshot. These file manifests are key to understanding the iceberg file layout.
Let’s look at the metadata file hierarchy mapping to the parquet data after the two insert operations.
Metadata JSON
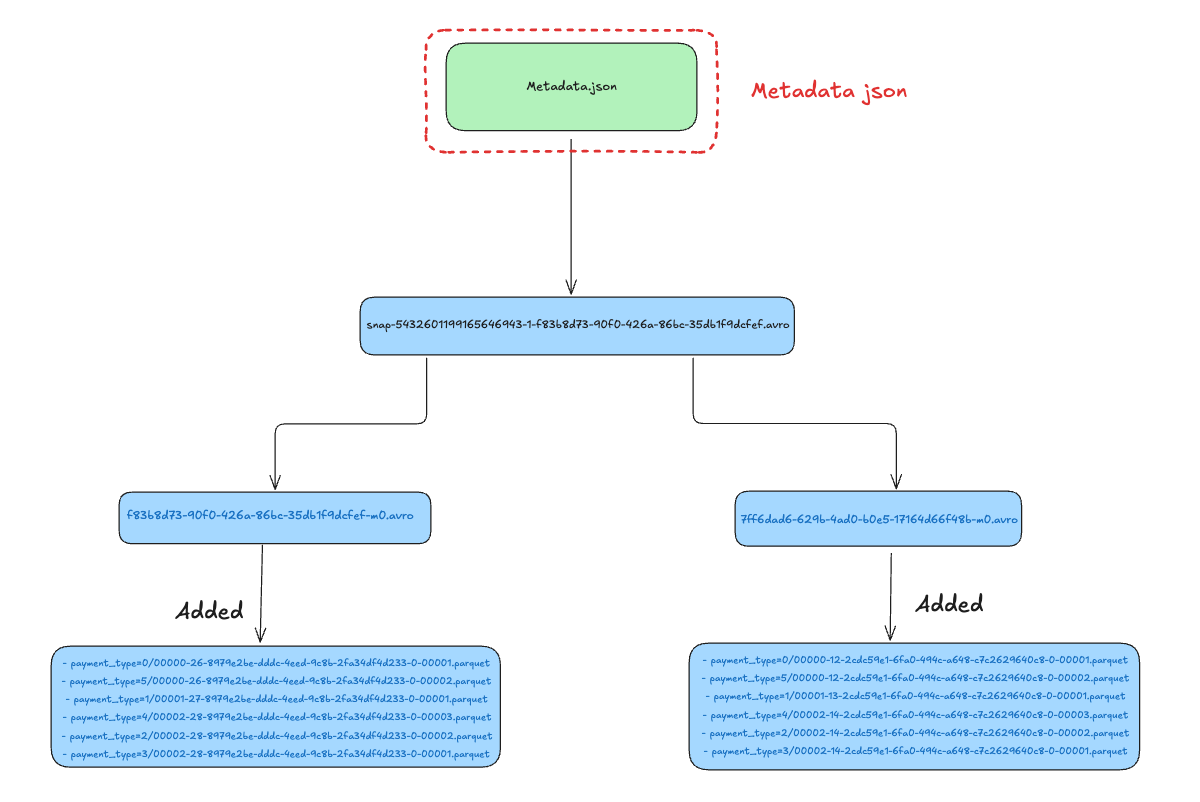 The metadata JSON file is in the root file of the snapshot, and it contains details about the schema of the table, current snapshot ID information, the manifest list file, and other statistics. You can find the complete metadata here.
The metadata JSON file is in the root file of the snapshot, and it contains details about the schema of the table, current snapshot ID information, the manifest list file, and other statistics. You can find the complete metadata here.
This file details the current snapshot and the manifest files associated with it. Apart from the current snapshot, it stores the snapshot history and the parent snapshot ID to determine the previous snapshot. This structure is fundamental to enabling iceberg time travel functionality.
{
"format-version" : 2,
"table-uuid" : "6f592606-eb09-412e-98bc-39c7fbfded20",
{.....}, //schema and other statistics
"current-snapshot-id" : 5432601199165646943,
"refs" : {
"main" : {
"snapshot-id" : 5432601199165646943,
"type" : "branch"
}
},
"snapshots" : [
{
"sequence-number" : 1,
"snapshot-id" : 7622004712011297851,
"timestamp-ms" : 1733766006396,
"summary" : {
"operation" : "append",
"spark.app.id" : "local-1733765667302",
"added-data-files" : "6",
"added-records" : "2463931",
"added-files-size" : "37853537",
"changed-partition-count" : "6",
"total-records" : "2463931",
"total-files-size" : "37853537",
"total-data-files" : "6",
"total-delete-files" : "0",
"total-position-deletes" : "0",
"total-equality-deletes" : "0"
},
"manifest-list" : "s3://lakehouse/nyc/taxis_partitioned/metadata/snap-7622004712011297851-1-7ff6dad6-629b-4ad0-b0e5-17164d66f48b.avro",
"schema-id" : 0
}, //first append snapshot
{
"sequence-number" : 2,
"snapshot-id" : 5432601199165646943,
"parent-snapshot-id" : 7622004712011297851,
"timestamp-ms" : 1733766011419,
"summary" : {
"operation" : "append",
"spark.app.id" : "local-1733765667302",
"added-data-files" : "6",
"added-records" : "2979431",
"added-files-size" : "45390848",
"changed-partition-count" : "6",
"total-records" : "5443362",
"total-files-size" : "83244385",
"total-data-files" : "12",
"total-delete-files" : "0",
"total-position-deletes" : "0",
"total-equality-deletes" : "0"
},
"manifest-list" : "s3://lakehouse/nyc/taxis_partitioned/metadata/snap-5432601199165646943-1-f83b8d73-90f0-426a-86bc-35db1f9dcfef.avro",
"schema-id" : 0
}
]
}
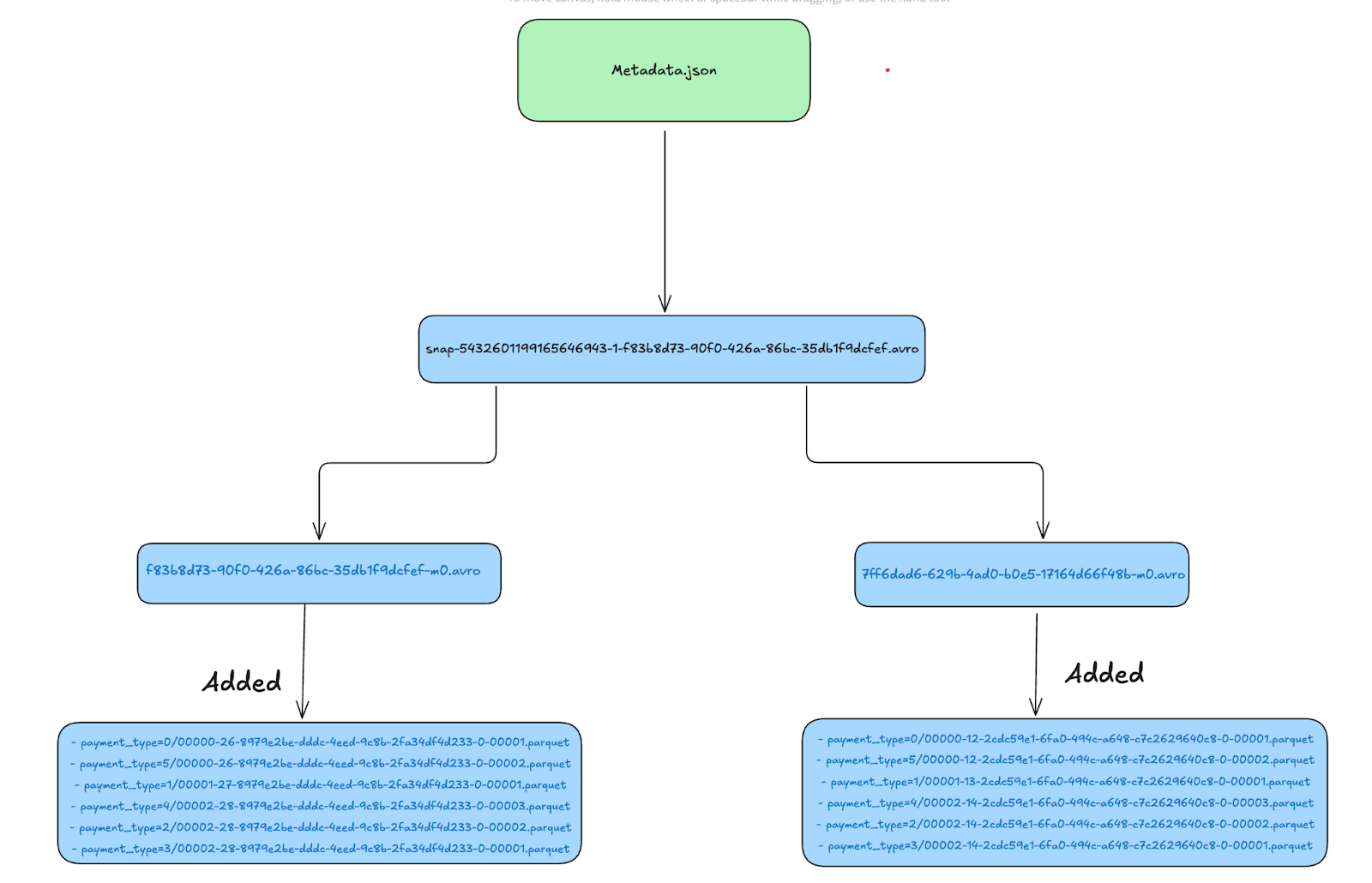
Manifest List Files
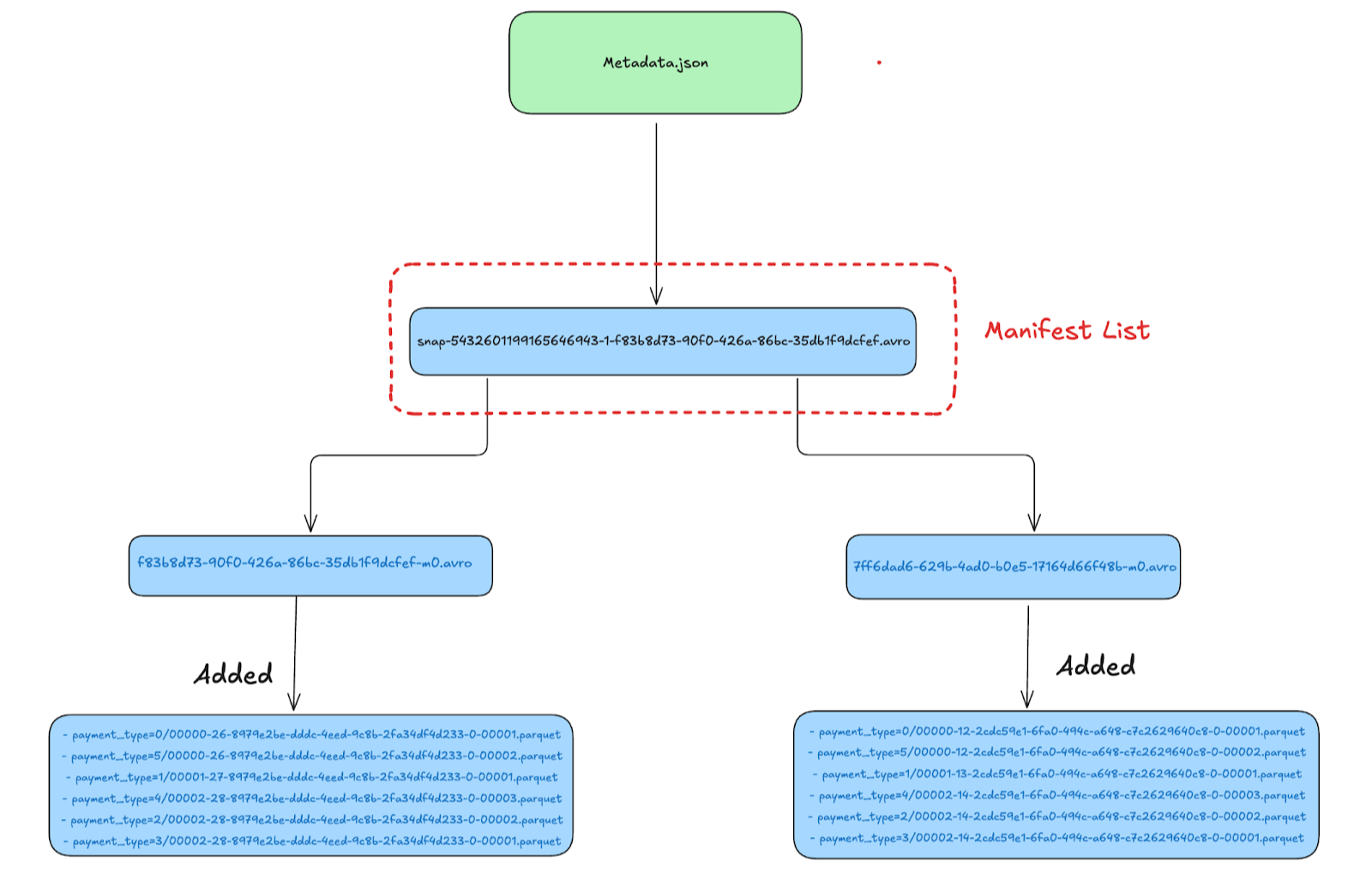 The Manifest list contains the manifest files that are part of a snapshot and additional details, such as the number of data files added or deleted. This structure is part of what makes Apache Iceberg's file IO operations so efficient.
The Manifest list contains the manifest files that are part of a snapshot and additional details, such as the number of data files added or deleted. This structure is part of what makes Apache Iceberg's file IO operations so efficient.
| Manifest Path |
|--------------------------------------------------------------------------------------------|
| s3://lakehouse/nyc/taxis_partitioned/metadata/f83b8d73-90f0-426a-86bc-35db1f9dcfef-m0.avro |
| s3://lakehouse/nyc/taxis_partitioned/metadata/7ff6dad6-629b-4ad0-b0e5-17164d66f48b-m0.avro |
Manifest Files
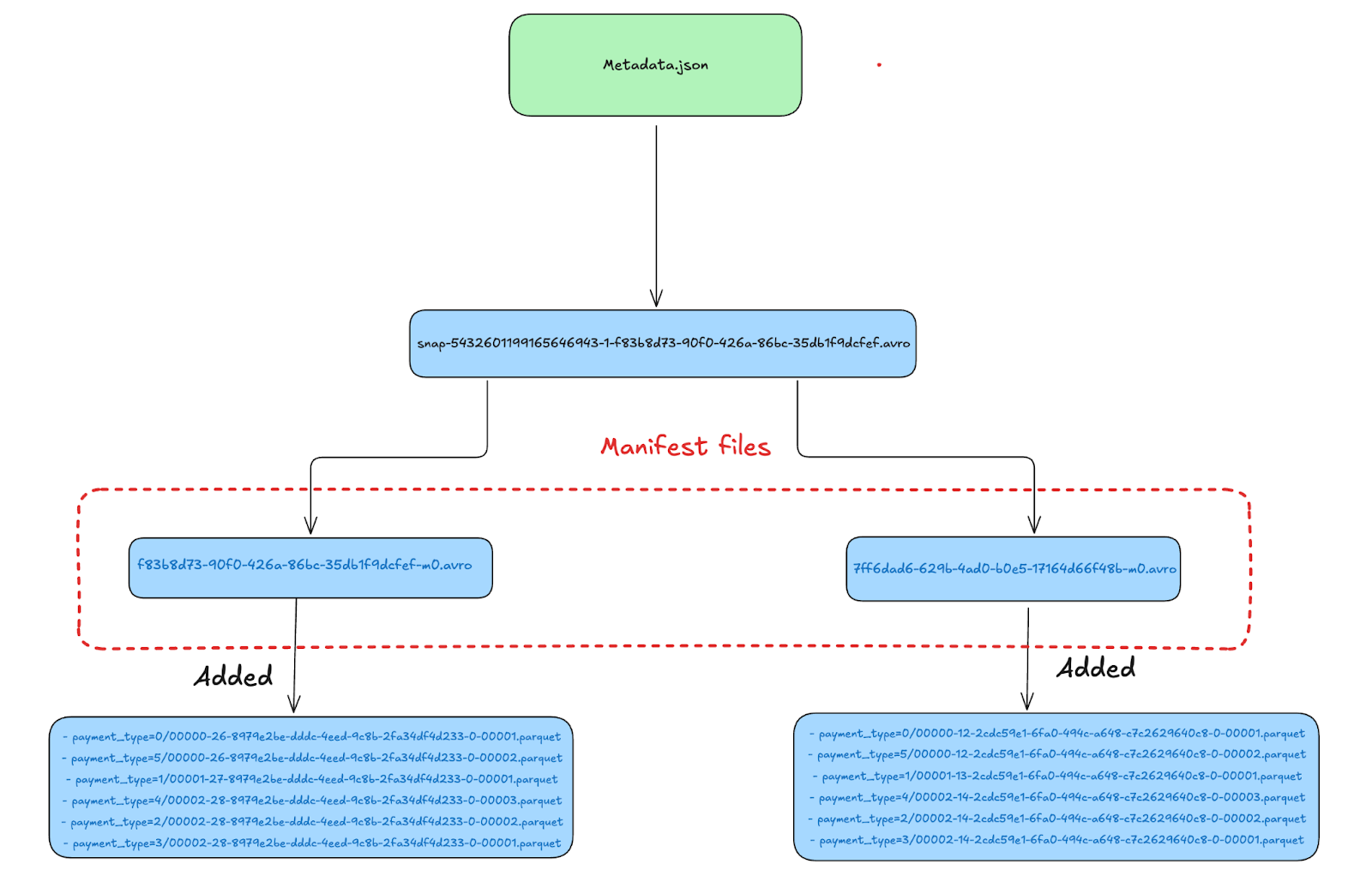 Looking closer into the
Looking closer into the f83b8d73-90f0-426a-86bc-35db1f9dcfef-m0.avro avro manifest file we see that this points to 6 data files with status 1
| Status | File Path |
|--------|------------------------------------------------------------------------------------------------------------------------|
| 1 | s3://lakehouse/nyc/taxis_partitioned/data/payment_type=0/00000-26-8979e2be-dddc-4eed-9c8b-2fa34df4d233-0-00001.parquet |
| 1 | s3://lakehouse/nyc/taxis_partitioned/data/payment_type=5/00000-26-8979e2be-dddc-4eed-9c8b-2fa34df4d233-0-00002.parquet |
| 1 | s3://lakehouse/nyc/taxis_partitioned/data/payment_type=1/00001-27-8979e2be-dddc-4eed-9c8b-2fa34df4d233-0-00001.parquet |
| 1 | s3://lakehouse/nyc/taxis_partitioned/data/payment_type=4/00002-28-8979e2be-dddc-4eed-9c8b-2fa34df4d233-0-00003.parquet |
| 1 | s3://lakehouse/nyc/taxis_partitioned/data/payment_type=2/00002-28-8979e2be-dddc-4eed-9c8b-2fa34df4d233-0-00002.parquet |
| 1 | s3://lakehouse/nyc/taxis_partitioned/data/payment_type=3/00002-28-8979e2be-dddc-4eed-9c8b-2fa34df4d233-0-00001.parquet |
7ff6dad6-629b-4ad0-b0e5-17164d66f48b-m0.avro manifest file:
| Status | File Path |
|--------|------------------------------------------------------------------------------------------------------------------------|
| 1 | s3://lakehouse/nyc/taxis_partitioned/data/payment_type=0/00000-12-2cdc59e1-6fa0-494c-a648-c7c2629640c8-0-00001.parquet |
| 1 | s3://lakehouse/nyc/taxis_partitioned/data/payment_type=5/00000-12-2cdc59e1-6fa0-494c-a648-c7c2629640c8-0-00002.parquet |
| 1 | s3://lakehouse/nyc/taxis_partitioned/data/payment_type=1/00001-13-2cdc59e1-6fa0-494c-a648-c7c2629640c8-0-00001.parquet |
| 1 | s3://lakehouse/nyc/taxis_partitioned/data/payment_type=4/00002-14-2cdc59e1-6fa0-494c-a648-c7c2629640c8-0-00003.parquet |
| 1 | s3://lakehouse/nyc/taxis_partitioned/data/payment_type=2/00002-14-2cdc59e1-6fa0-494c-a648-c7c2629640c8-0-00002.parquet |
| 1 | s3://lakehouse/nyc/taxis_partitioned/data/payment_type=3/00002-14-2cdc59e1-6fa0-494c-a648-c7c2629640c8-0-00001.parquet |
The Consequence of Compaction
We have reviewed the iceberg metadata state after the two insert operations. Now, let us understand what happens when we do a compaction job on it.
Compaction in Iceberg is a replace operation that takes multiple smaller files and rewrites them into fewer, larger files to improve query efficiency. This process is also known as iceberg merge or merge on read. The goals of data file compaction are:
- Reducing file counts:
- Reduce the number of data files.
- Reduce the number of deleted files.
- Improving data locality:
- Apply data clustering to make reads more efficient.
When we run an Iceberg Compaction operation (Amoro in this case), Iceberg creates a new snapshot and updates the metadata accordingly. This process is crucial for data storage optimization and maintaining optimal data file size. The compaction process involves specific rewrite strategies to ensure optimal performance.
Compaction is not typically performed over an entire table, as the table is too large. Instead, compaction jobs run periodically: either hourly or in other specific configurations. This approach helps manage throttling and ensures consistent performance.
Setting Up Amoro Configuration
Finally, the premise is set to run the compaction job; we’ll now use Apache Amoro to compact the Iceberg Tables. Let’s set it up Apache Amoro first.
Creating Optimizer Group
Optimizer in Amoro is a component responsible for executing self-optimizing tasks. It is a resident process managed by AMS (Amoro Management Service). AMS is a service responsible for detecting and planning Self-optimizing tasks for tables and then scheduling them with Optimizers for distributed execution in real time.
Amoro is already up and running from dockers-compose. Open http://localhost:1630 in a browser, and enter admin/admin to log in to the dashboard. Click on Optimizing in the sidebar, choose Optimizer Groups, and click Add Group button to create a new group before creating the catalog:
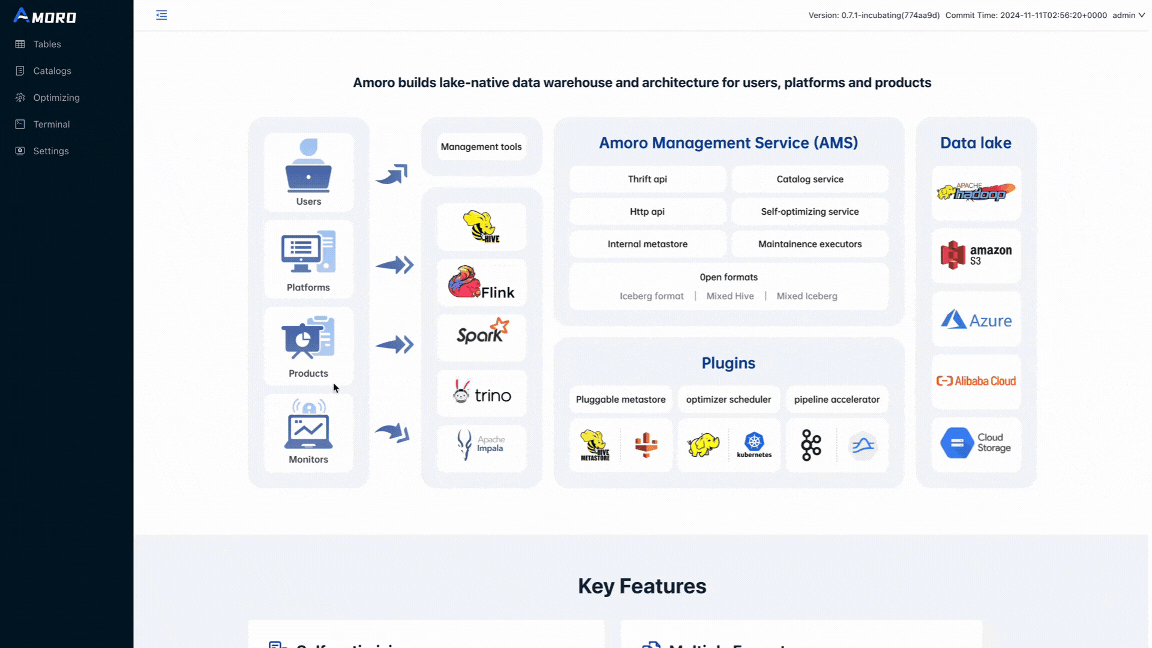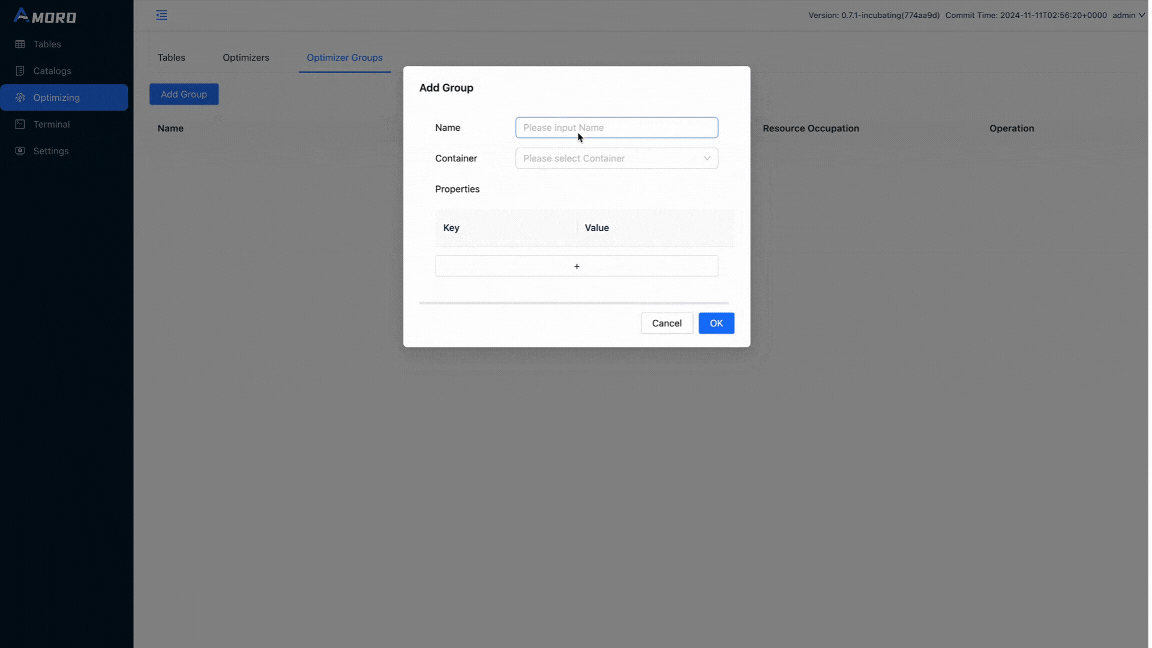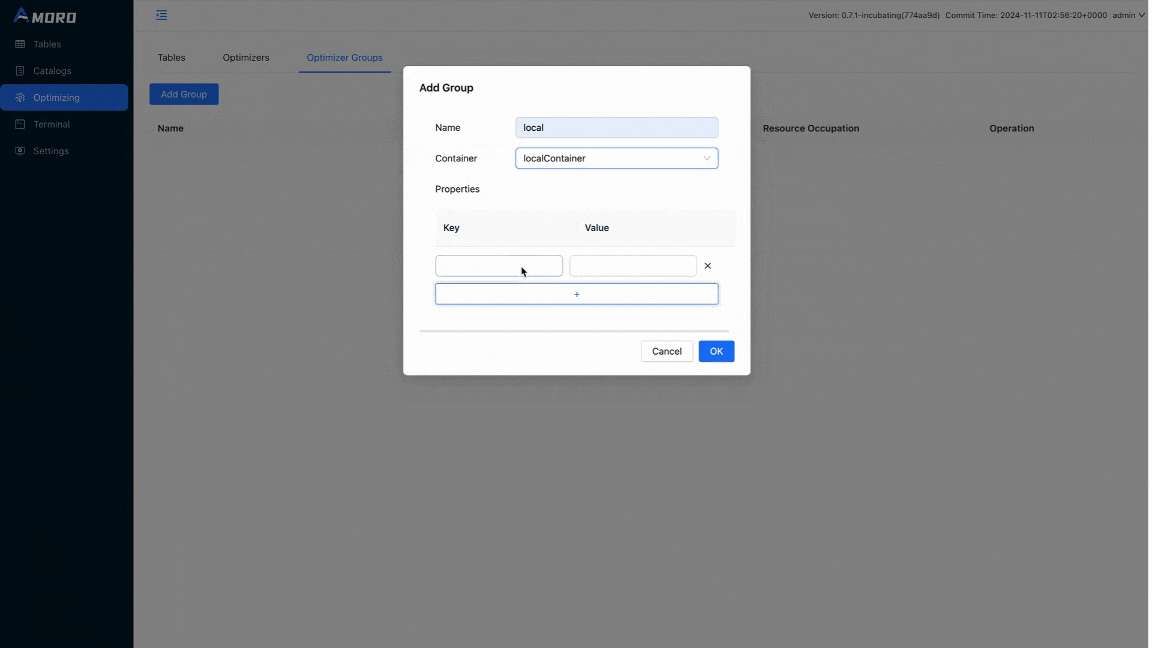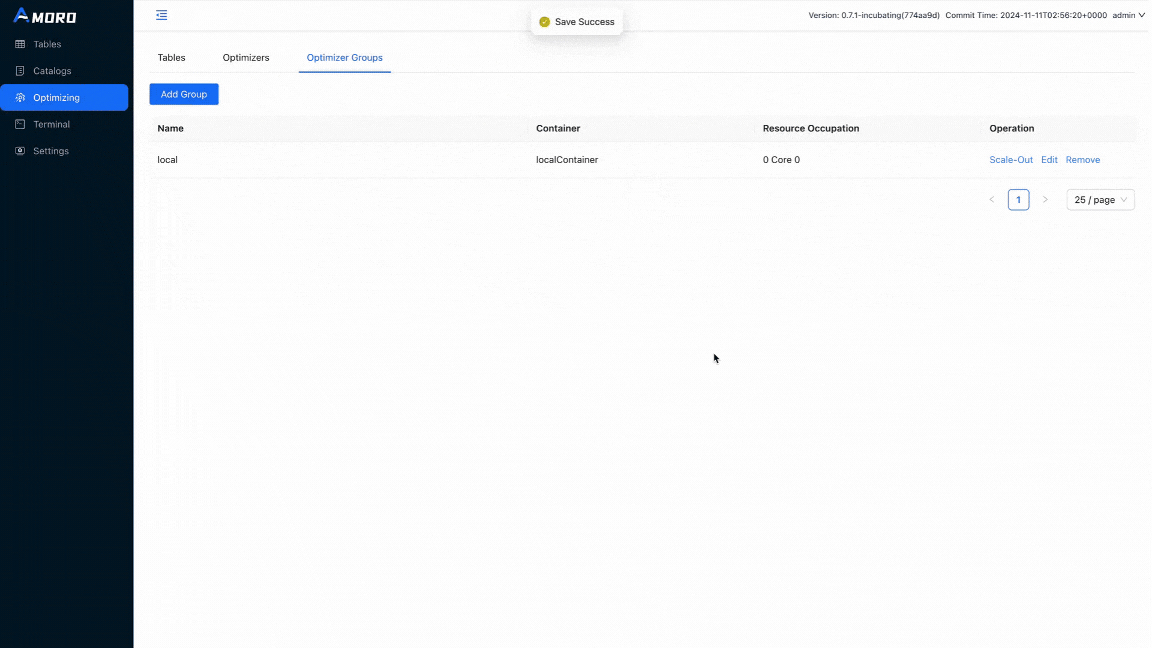
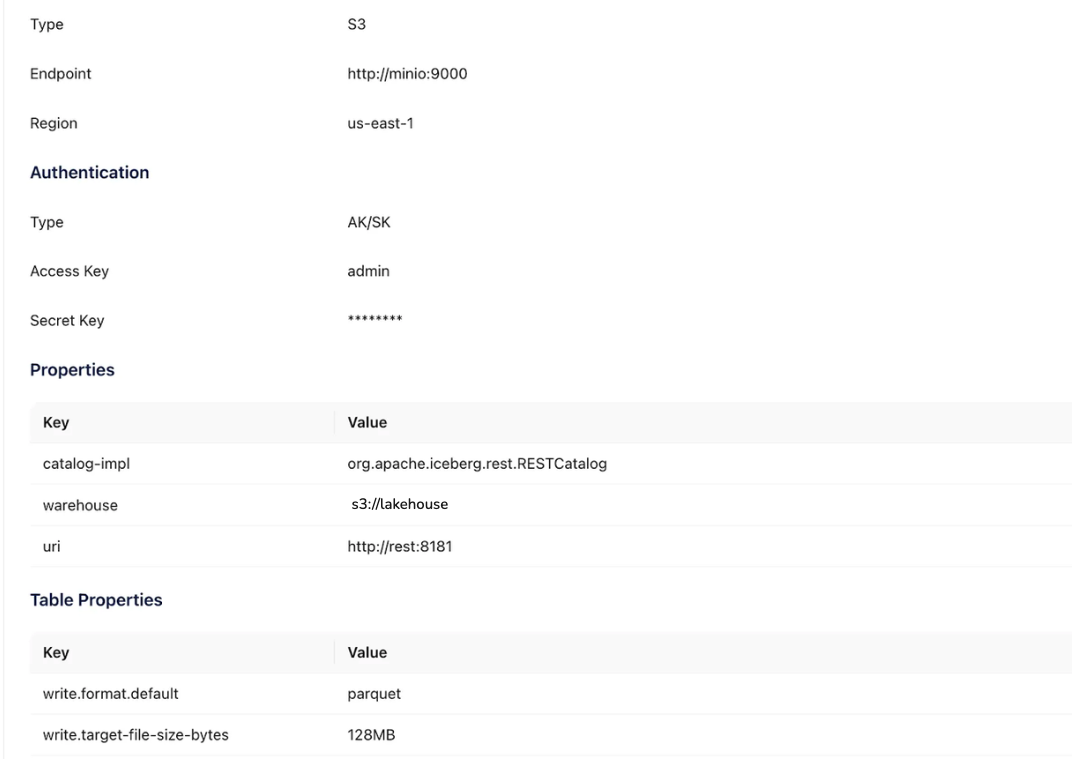
Click on Catalogs in the sidebar and click on the + button under Catalog List to create an external catalog with metastore as custom and these configurations:
Click on Optimizing in the sidebar, select the Optimizer Group tab, and click the scale-out operation for the group local. Set the concurrency of the optimizer to 1 and click OK.
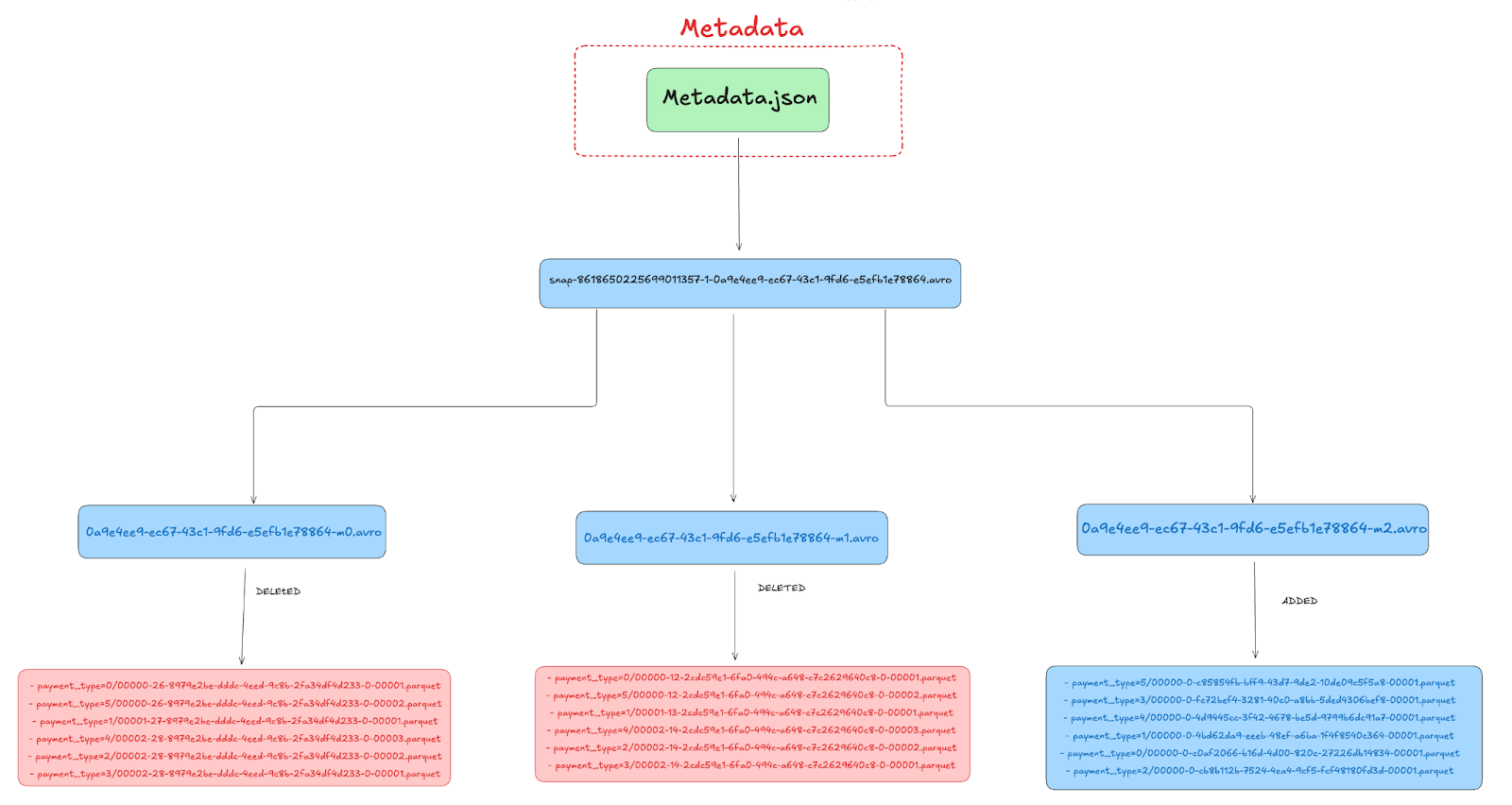
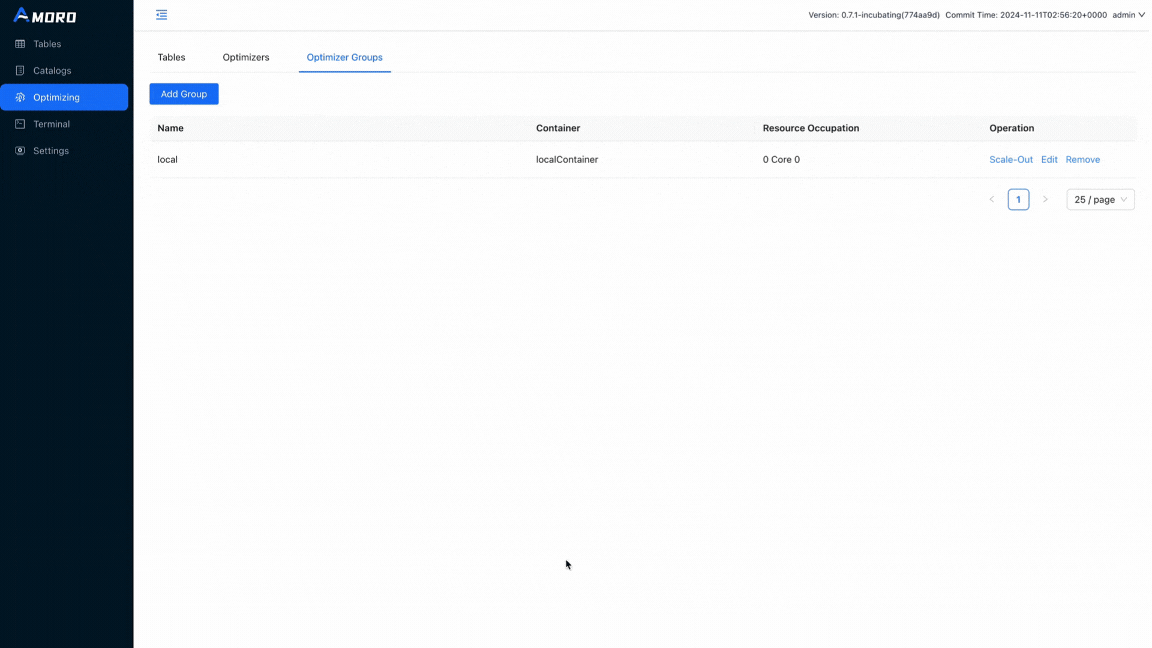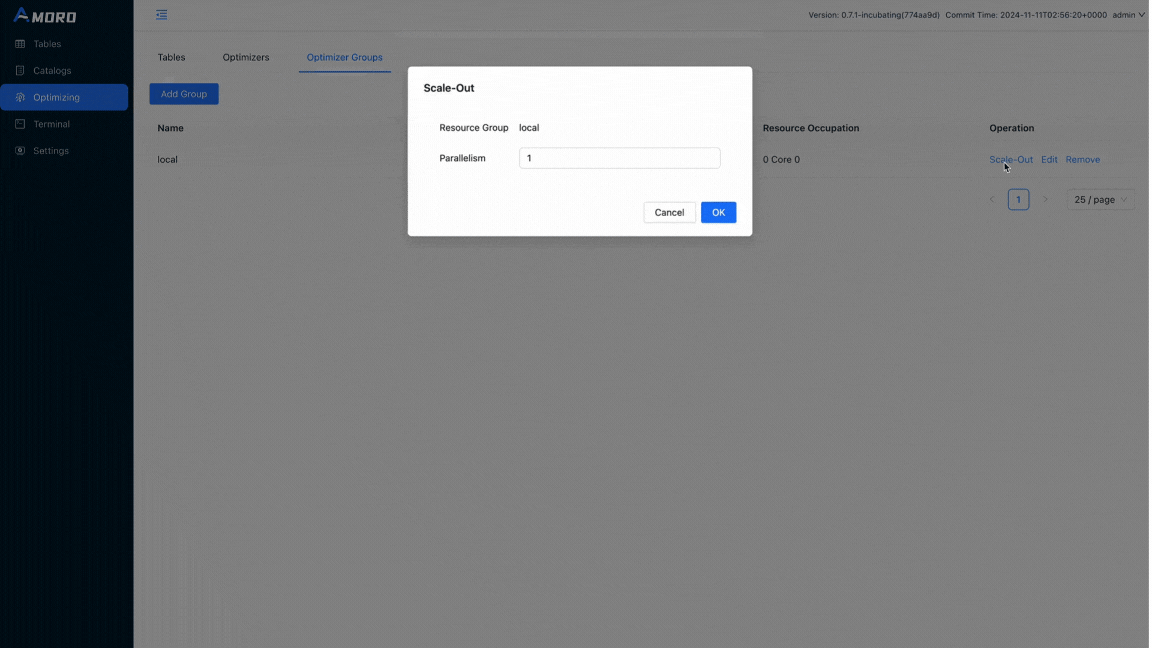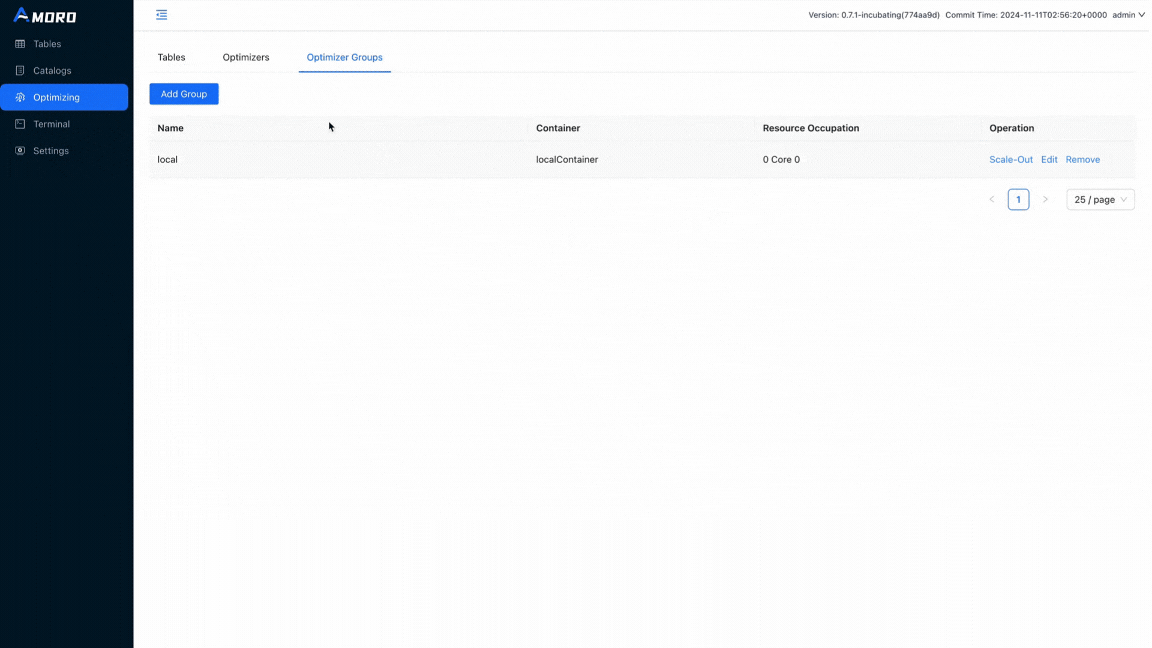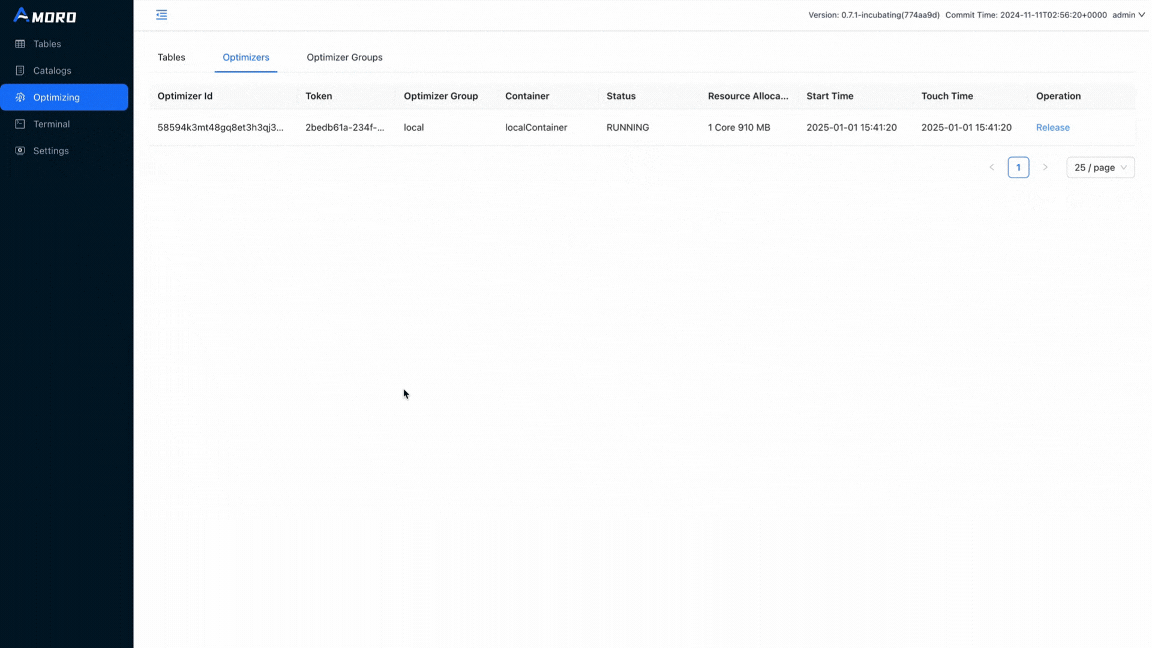 Let’s see what the metadata looks like after compaction:
Let’s see what the metadata looks like after compaction:
{
"format-version" : 2,
"table-uuid" : "6f592606-eb09-412e-98bc-39c7fbfded20",
"location" : "s3://lakehouse/nyc/taxis_partitioned",
"last-sequence-number" : 3,
{....} //schema and other stats
"current-snapshot-id" : 8618650225699011357,
"refs" : {
"main" : {
"snapshot-id" : 8618650225699011357,
"type" : "branch"
}
},
"snapshots" : [
{....} //first insert snapshot
{....}, //second insert snapshot,
{
"sequence-number" : 3,
"snapshot-id" : 8618650225699011357,
"parent-snapshot-id" : 5432601199165646943,
"timestamp-ms" : 1733766121819,
"summary" : {
"operation" : "replace",
"snapshot.producer" : "OPTIMIZE",
"added-data-files" : "6",
"deleted-data-files" : "12",
"added-records" : "5443362",
"deleted-records" : "5443362",
"added-files-size" : "82592078",
"removed-files-size" : "83244385",
"changed-partition-count" : "6",
"total-records" : "5443362",
"total-files-size" : "82592078",
"total-data-files" : "6",
"total-delete-files" : "0",
"total-position-deletes" : "0",
"total-equality-deletes" : "0"
},
"manifest-list" : "s3://lakehouse/nyc/taxis_partitioned/metadata/snap-8618650225699011357-1-0a9e4ee9-ec67-43c1-9fd6-e5efb1e78864.avro",
"schema-id" : 0
}
]
}Notice the summary for this new snapshot (with ID 8618650225699011357):
- "operation" : "replace" - this mentions that this operation is a replace operation in this snapshot.
added-data-files: 6 – The compaction produced 6 new, larger, consolidated files.deleted-data-files: 12 – All original 12 files (from the first two appends) were replaced.
This means that after compaction, the table returns to having 6 data files. However, these 6 are different (larger, combined) files replacing the original 12.
If we inspect the Manifest List after compaction, we see three manifest entries:
Snap-8618650225699011357-1-0a9e4ee9-ec67-43c1-9fd6-e5efb1e78864.avro
Manifest List
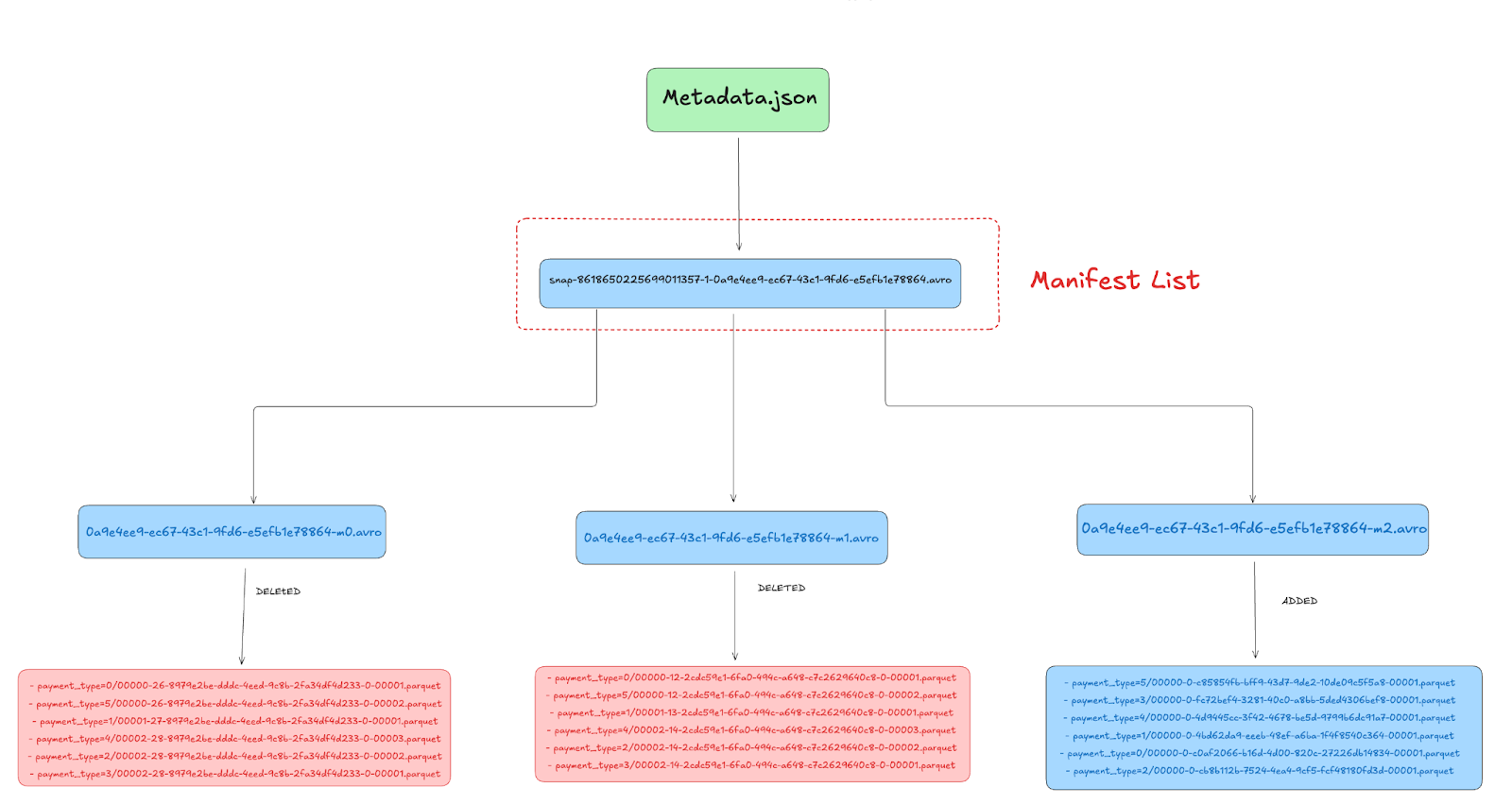 Here the new manifest list after compaction points to 3 manifest files
Here the new manifest list after compaction points to 3 manifest files
| Manifest Path |
|-----------------------------------------------------------------------------------------------|
| s3://lakehouse/nyc/taxis_partitioned/metadata/0a9e4ee9-ec67-43c1-9fd6-e5efb1e78864-m2.avro |
| s3://lakehouse/nyc/taxis_partitioned/metadata/0a9e4ee9-ec67-43c1-9fd6-e5efb1e78864-m0.avro |
| s3://lakehouse/nyc/taxis_partitioned/metadata/0a9e4ee9-ec67-43c1-9fd6-e5efb1e78864-m1.avro |Manifest Files
Let’s go over each of the three manifest files after compaction and see how they have changed.
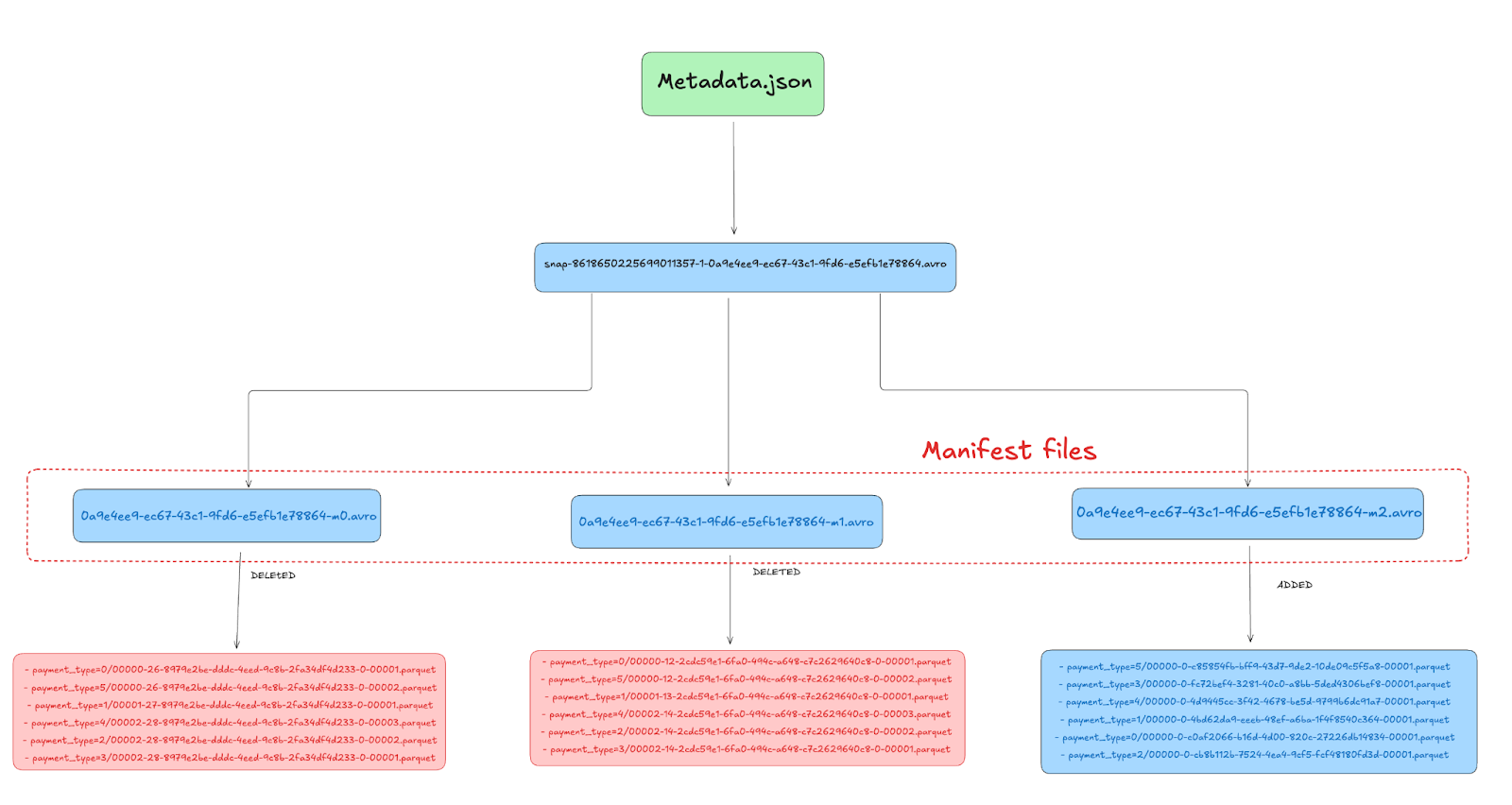 First manifest file
First manifest file 0a9e4ee9-ec67-43c1-9fd6-e5efb1e78864-m1.avro
| Status | File Path |
|--------|------------------------------------------------------------------------------------------------------------------------|
| 2 | s3://lakehouse/nyc/taxis_partitioned/data/payment_type=0/00000-12-2cdc59e1-6fa0-494c-a648-c7c2629640c8-0-00001.parquet |
| 2 | s3://lakehouse/nyc/taxis_partitioned/data/payment_type=5/00000-26-8979e2be-dddc-4eed-9c8b-2fa34df4d233-0-00002.parquet |
| 2 | s3://lakehouse/nyc/taxis_partitioned/data/payment_type=1/00001-27-8979e2be-dddc-4eed-9c8b-2fa34df4d233-0-00001.parquet |
| 2 | s3://lakehouse/nyc/taxis_partitioned/data/payment_type=4/00002-28-8979e2be-dddc-4eed-9c8b-2fa34df4d233-0-00003.parquet |
| 2 | s3://lakehouse/nyc/taxis_partitioned/data/payment_type=2/00002-28-8979e2be-dddc-4eed-9c8b-2fa34df4d233-0-00002.parquet |
| 2 | s3://lakehouse/nyc/taxis_partitioned/data/payment_type=3/00002-28-8979e2be-dddc-4eed-9c8b-2fa34df4d233-0-00001.parquet |- payment_type=0/00000-12-2cdc59e1-6fa0-494c-a648-c7c2629640c8-0-00001.parquet
- payment_type=5/00000-12-2cdc59e1-6fa0-494c-a648-c7c2629640c8-0-00002.parquet
- payment_type=1/00001-13-2cdc59e1-6fa0-494c-a648-c7c2629640c8-0-00001.parquet
- payment_type=4/00002-14-2cdc59e1-6fa0-494c-a648-c7c2629640c8-0-00003.parquet
- payment_type=2/00002-14-2cdc59e1-6fa0-494c-a648-c7c2629640c8-0-00002.parquet
- payment_type=3/00002-14-2cdc59e1-6fa0-494c-a648-c7c2629640c8-0-00001.parquet
0a9e4ee9-ec67-43c1-9fd6-e5efb1e78864-m0.avro
| Status | File Path |
|--------|------------------------------------------------------------------------------------------------------------------------|
| 2 | s3://lakehouse/nyc/taxis_partitioned/data/payment_type=0/00000-26-8979e2be-dddc-4eed-9c8b-2fa34df4d233-0-00001.parquet |
| 2 | s3://lakehouse/nyc/taxis_partitioned/data/payment_type=5/00000-26-8979e2be-dddc-4eed-9c8b-2fa34df4d233-0-00002.parquet |
| 2 | s3://lakehouse/nyc/taxis_partitioned/data/payment_type=1/00001-27-8979e2be-dddc-4eed-9c8b-2fa34df4d233-0-00001.parquet |
| 2 | s3://lakehouse/nyc/taxis_partitioned/data/payment_type=4/00002-28-8979e2be-dddc-4eed-9c8b-2fa34df4d233-0-00003.parquet |
| 2 | s3://lakehouse/nyc/taxis_partitioned/data/payment_type=2/00002-28-8979e2be-dddc-4eed-9c8b-2fa34df4d233-0-00002.parquet |
| 2 | s3://lakehouse/nyc/taxis_partitioned/data/payment_type=3/00002-28-8979e2be-dddc-4eed-9c8b-2fa34df4d233-0-00001.parquet |- payment_type=0/00000-26-8979e2be-dddc-4eed-9c8b-2fa34df4d233-0-00001.parquet
- payment_type=5/00000-26-8979e2be-dddc-4eed-9c8b-2fa34df4d233-0-00002.parquet
- payment_type=1/00001-27-8979e2be-dddc-4eed-9c8b-2fa34df4d233-0-00001.parquet
- payment_type=4/00002-28-8979e2be-dddc-4eed-9c8b-2fa34df4d233-0-00003.parquet
- payment_type=2/00002-28-8979e2be-dddc-4eed-9c8b-2fa34df4d233-0-00002.parquet
- payment_type=3/00002-28-8979e2be-dddc-4eed-9c8b-2fa34df4d233-0-00001.parquet
0a9e4ee9-ec67-43c1-9fd6-e5efb1e78864-m2.avro
| Status | File Path |
|--------|------------------------------------------------------------------------------------------------------------------------|
| 2 | s3://lakehouse/nyc/taxis_partitioned/data/payment_type=0/00000-26-8979e2be-dddc-4eed-9c8b-2fa34df4d233-0-00001.parquet |
| 2 | s3://lakehouse/nyc/taxis_partitioned/data/payment_type=5/00000-26-8979e2be-dddc-4eed-9c8b-2fa34df4d233-0-00002.parquet |
| 2 | s3://lakehouse/nyc/taxis_partitioned/data/payment_type=1/00001-27-8979e2be-dddc-4eed-9c8b-2fa34df4d233-0-00001.parquet |
| 2 | s3://lakehouse/nyc/taxis_partitioned/data/payment_type=4/00002-28-8979e2be-dddc-4eed-9c8b-2fa34df4d233-0-00003.parquet |
| 2 | s3://lakehouse/nyc/taxis_partitioned/data/payment_type=2/00002-28-8979e2be-dddc-4eed-9c8b-2fa34df4d233-0-00002.parquet |
| 2 | s3://lakehouse/nyc/taxis_partitioned/data/payment_type=3/00002-28-8979e2be-dddc-4eed-9c8b-2fa34df4d233-0-00001.parquet |- payment_type=5/00000-0-c85854fb-bff9-43d7-9de2-10de09c5f5a8-00001.parquet
- payment_type=3/00000-0-fc72bef4-3281-40c0-a8bb-5ded4306bef8-00001.parquet
- payment_type=4/00000-0-4d9445cc-3f42-4678-be5d-9799b6dc91a7-00001.parquet
- payment_type=1/00000-0-4bd62da9-eeeb-48ef-a6ba-1f4f8540c364-00001.parquet
- payment_type=0/00000-0-c0af2066-b16d-4d00-820c-27226db14834-00001.parquet
- payment_type=2/00000-0-cb8b112b-7524-4ea4-9cf5-fcf48180fd3d-00001.parquet
Table State Before and After the Compaction Process
Before Compaction
Before compaction, the Metadata JSON referenced 2 snapshots and the current snapshot manifest list file contained 2 manifest files. Each of these manifest files listed 6 data files, resulting in 12 total data files distributed across the 2 manifest files.
After Compaction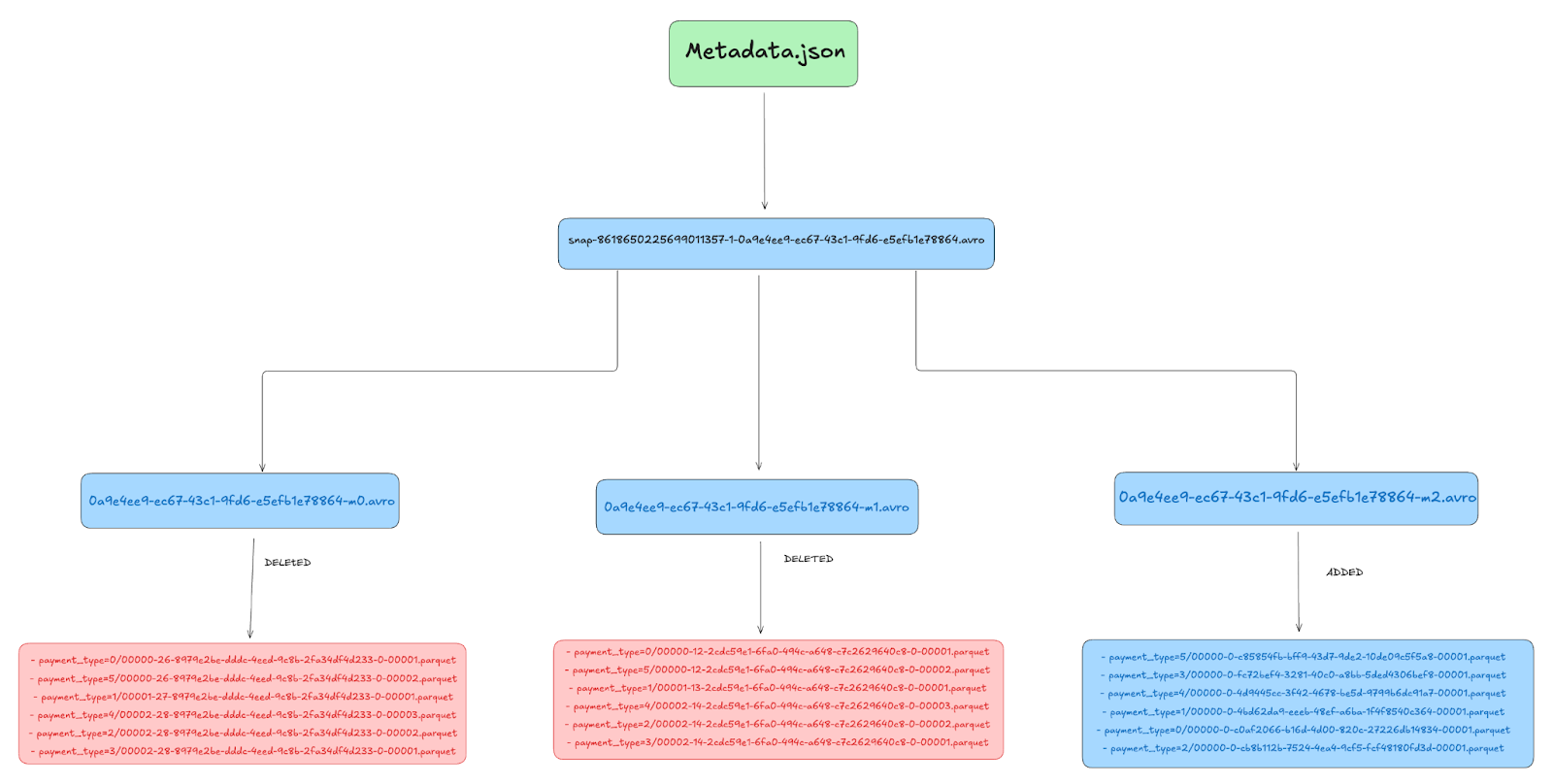
After compaction, the new Metadata JSON references a manifest list file containing three new manifests. While two manifests mark 12 old files as deleted, the third manifest lists newly added compacted files, resulting in 6 new files replacing the 12 deleted ones.
Let’s see what the metadata folder in the iceberg table looks like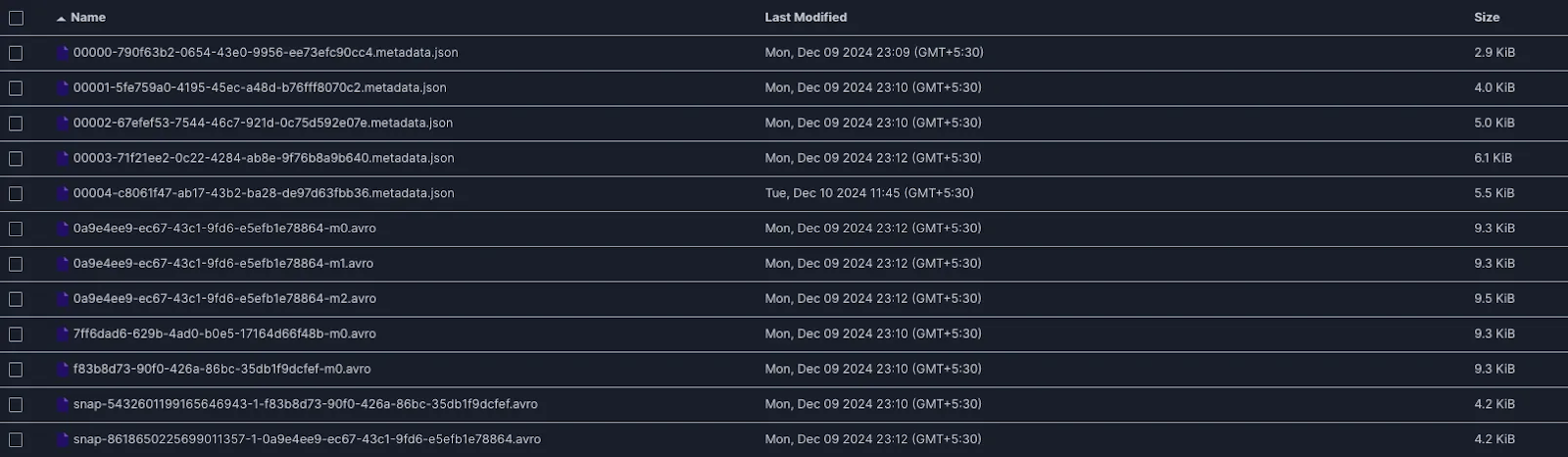 After the compaction snapshot, the query engine will only see the new, consolidated set of 6 files. Iceberg appends metadata, creating immutable snapshots. Each snapshot (manifest list file) references manifests that track which files are added or removed. Older snapshots are still preserved for time-travel queries, so you can revisit a previous snapshot and see the old files. The current state of the table is more optimized and efficient for queries going forward.
After the compaction snapshot, the query engine will only see the new, consolidated set of 6 files. Iceberg appends metadata, creating immutable snapshots. Each snapshot (manifest list file) references manifests that track which files are added or removed. Older snapshots are still preserved for time-travel queries, so you can revisit a previous snapshot and see the old files. The current state of the table is more optimized and efficient for queries going forward.Conclusion
This hands-on tutorial taught us how metadata looks before and after compaction and the under-the-hood view of how compaction works. This metadata management approach and file organization sets the Apache Iceberg apart from traditional data warehouse solutions and other lakehouse formats. It allows for efficient querying, easy rollback capabilities, and flexible schema evolution. It is an excellent choice for building a modern data lakehouse on high-performance object storage systems like MinIO or S3.
By utilizing Apache Iceberg’s advanced features and optimizing through processes like compaction, organizations can build highly performant and flexible data analytics platforms that can handle massive scale while maintaining the agility needed for modern data-driven decision-making.
We’ll be soon back with more exciting hands-on tutorials; till then stay tuned and keep building!